
[Review] YOLO v2
[Paper review] YOLO_v2
이전 포스팅의 YOLO v1에 후속 버전인 YOLO v2에 대해 리뷰해보고자 합니다.
Redmon, Joseph, and Ali Farhadi. “YOLO9000: better, faster, stronger.” Proceedings of the IEEE conference on computer vision and pattern recognition (2017)
본 논문의 구성은 독특하게도 Better, Faster, Stronger의 세 파트로 구성되어 있습니다.
각각 어떻게 이전 버전을 업데이트하고 발전시켰는 지를 소개하고 있는데요. 하나씩 살펴보겠습니다.
(본 리뷰의 모든 수식과 그림은 원 논문을 참고했습니다.)
Better
제목에서부터 느낌이 오듯이 Better 파트에서는 이전 YOLO v1의 성능 개선이 주요 포인트입니다. 저자는 YOLO v1의 주요 문제점으로 두 가지를 꼽는데요, Localization 오류와 Low recall입니다. YOLO v2에서는 이를 해결하기 위한 다양한 방법들이 소개되고 있습니다. 그 중에서도 주요 포인트들만 공부해보겠습니다.
- Convolutional With Anchor Boxes
YOLO에서는 output을 위한 final layer가 fully connected layer였습니다. YOLO v2에서는 이를 Faster R-CNN 등 다른 모델들과 같이 Convolutional layer로 바꿨습니다. 또한 각 region domain에서 object class를 정했었는데 이를 Anchor box를 도입하여 대체했습니다. Anchor box는 임의로 배치된 box들의 정보를 통해 도움을 받아 object를 detection하는 방법입니다. YOLO에서는 v2에서 최초로 적용되었네요! 이는 지난 포스팅에서도 언급했었던 YOLO v1의 regional based approach의 한계점을 개선하는 효과가 있습니다.
YOLO v2는 Anchor box도입으로 정확성 측면에선 다소 떨어졌지만 (기존 region based predict에서 보다 box의 숫자들이 상당히 많이 늘어나기 때문에 accuracy 측면에선 불리합니다.) recall 측면에서 81%에서 88%까지 개선이 이루어졌습니다.
- Dimension Clusters
Anchor box를 도입하고나니 문제가 생겼습니다. 얼마나 많은 Anchor box를 설정할지, 어떤 위치에 설정할지를 결정해야 하는 것이죠! 기존의 모델들은 사람이 임의로 hand-picked의 방식으로 이를 설정해주었습니다. 본 논문에서는 training set의 box들의 centroid 좌표를 이용하여 K-means clustering을 통해 Anchor box의 사전 정보(논문에서 prior)를 결정해줍니다.
이 때, 기존의 K-means처럼 Euclidean distance를 이용하면 아무래도 면적이 큰, centroid와 박스 coordinate의 거리가 큰 box들은 문제가 생길 여지가 많기 때문에 custom distance를 사용합니다. 이를 Average IOU라 부릅니다.
\[\begin{gathered} d(box, centroid) = 1-IOU(box, centroid) \end{gathered}\]
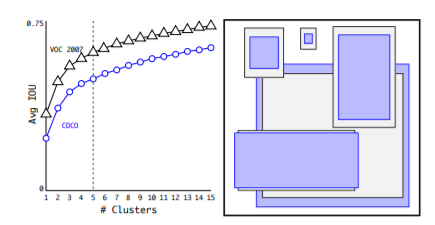
위 플랏을 보시면 k가 5일 때 비교적 높은 Avg. IOU를 기록함을 확인할 수 있습니다. 저자들은 model의 complexity를 낮추면서 가장 높은 IOU를 담보할 수 있는 k값이 5라고 생각하고 Anchor box의 사전 개수를 5개로 결정했습니다.
- Direct location prediction
Anchor box 도입은 두 번째 문제를 가져옵니다. 바로 모델이 instable 할 수 있다는 것입니다. Model은 box의 \((x,y)\) 좌표를 예측하게 되는데요. 이 때 아무런 restriction이 없다면 초기값에 따라 매우 불안정하게 box의 위치가 예측되고 (image domain 내에서 큰 변동) 이에 따라 모델이 stable한 결과를 내는데 불리해집니다.
이에 본 논문에서는 아래와 같은 계산을 통해 일종의 restriction을 만듭니다.
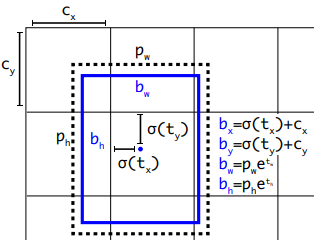
여기서 \(t_x, t_y, t_w, t_h, t_o\)가 model에서 예측치로 나오는 값들인데요! logistic activation (\(\sigma\)) 등을 통해서 \(b_x, b_y, b_w, b_h\)로 묶어둠으로써 model의 prediction을 stable하게 유지될 수 있도록 세팅합니다.
저자는 Dimension Clusters와 Direct location prediction 방법을 통해 5%의 mAP(정확성 지표) 개선을 얻었다고 설명합니다.
- Multi-Scale Training
YOLO v2는 다양한 size의 이미지들을 robust하게 학습하기 위해서 Multi-Scale training을 적용했습니다. 우선 위에서 살펴본 Anchor Box의 도입의 영향으로 YOLO v2의 기본 input size는 기존 448 x 448에서 416 x 416으로 바뀝니다. 하지만 Multi-Scale training은 매 iteration의 layer input을 고정하지 않고 매 10번의 batch가 지날 때마다 320 x 320에서 608 x 608 까지의 32간격으로 input size를 바꾸어 train을 진행합니다. 이렇게 하면 다양한 size에도 robust한 학습이 가능하며, 다양한 resolution의 이미지에 대해서도 학습이 가능하다는 장점이 있습니다.
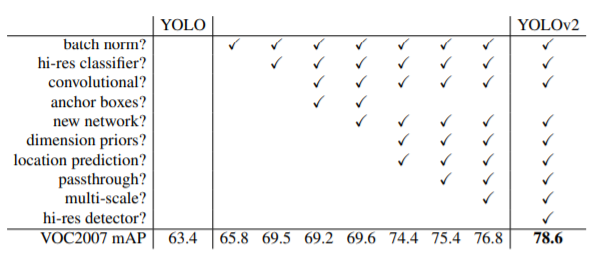
이 포스팅에서 다 다루지는 않았지만 이 외에도 Batch-normalization, Passthrough layer 등을 통해 YOLO v1 대비 mAP를 개선시켰습니다. VOC2007 mAP기준 63.4에서 78.6까지 높아졌음을 알 수 있네요!
Faster
안그래도 기존 detection method들 대비 속도가 뛰어났던 YOLO v1이었는데 Faster라니.. 어떻게 했을지 확인해보겠습니다.
- Darknet-19
YOLO v2가 발표될 당시 많은 detection method들은 base feature extractor scheme으로 VGG-16을 많이 사용하고 있었습니다. VGG-16은 계산량이 많기 때문에 빠른 스피드를 담보할 수 없는데요. 이에 저자들은 Googlenet architecture를 기반으로 독자적인 custom model을 만들어 사용했습니다. 그 것이 바로 Darknet-19입니다.
Darkent 19는 19 개의 convolutional layer와 5개의 maxpooling layer로 이루어진 구조를 가지고 있습니다. 저자는 이를 통해 정확도는 90.0% (VGG-16) 에서 88.0%로 매우 미세하게 줄어들었지만, 계산량 자체는 30.69 billion에서 8.52 billion으로 매우 줄어들어 훨씬 빠른 속도를 담보할 수 있다고 설명합니다.
이 외에도 Classification과 Detection을 위한 train과정을 각각 진행함으로써 model의 학습 및 예측 속도를 높였습니다.
Stronger
Stronger 파트는 제가 이 논문을 읽으면서 가장 흥미롭게 느꼈던 부분입니다. 앞서 Faster 파트에서 YOLO v2는 Classification과 Detection 과정을 따로 train한다고 언급했는데요! Classification을 training하는 ImageNet 1000 class classification dataset은 이름에서 알 수 있듯이 1,000개의 class가 존재합니다. 이에 비해 detection dataset은 20개의 class만 존재하기 때문에 matching이 되지 않죠! 이 부분을 해결해주는 파트가 Stronger입니다.
Class의 차이가 난다는 것이 어떤 문제점을 가져오는지 논문에서 예시로 설명하고 있습니다. 예를 들어, detection dataset에는 “DOG”이라는 class밖에 없는데, classification dataset에는 “Norfolk terrier”, “Yorkshire terrier”, “Bedlington terrier” 등의 보다 세분화된 class들이 존재한다는 것이죠! 이러한 문제를 해결해주기 위해서 저자는 Hierarchical tree를 사용합니다. Hierarchical tree의 개념은 아래 그림을 보면 좀 더 쉽게 알 수 있습니다.
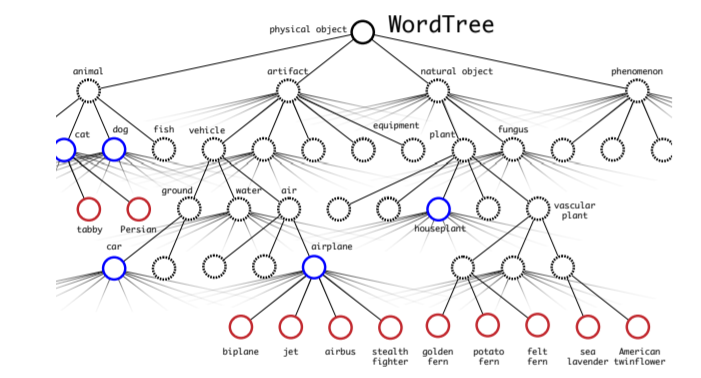
가장 상위 node에 Pyhsical object라고 하는 가장 큰 개념이 속해져있고 그 아래로 카테고리가 나눠지면서 단어들이 분류되어 위치하는 것을 확인할 수 있습니다. 이렇게 Tree를 만드는 목적 중 가장 중요한 것은 Probability를 계산할 수 있게 된다는 것입니다. Tree를 사용하지 않는다면 Classification object에서 Norfolk terrier가 나왔을 때 detection probability가 어떻게 계산될 지 알 수 없습니다. 하지만 tree를 이용한다면 root node로부터의 조건부 확률을 이용하여 간접적으로 확률을 구할 수 있게 됩니다!
\[P(\textit{Norfolk terrier})=P(\textit{Norfolk terrier }|\textit{ terrier}) * P(\textit{terrier }|\textit{ dog}) *\cdot\cdot\cdot * P(\textit{animal } | \textit{Physical Object})\]위의 수식을 보면 한결 이해하기가 쉽습니다. 이 때 제일 꼭대기 노드인 \(P(\textit{Physical Object})=1\)임을 가정합니다. 이런 식으로 구성된 확률 값을 가지고 dataset이 classification이라면 architecture의 classification 부분의 loss function으로 update하고 detection이라면 전체 모델의 loss function을 가지고 update해주게 됩니다.
이러한 class의 matching 및 확장은 굉장히 흥미로웠습니다. class의 규모가 다른 dataset들을 가지고 얼마든지 병합해서 training을 진행할 수 있다는 점에서 좋은 아이디어라고 느꼈습니다.
Experiment Results
이러한 노력들로 YOLO v2가 얼마나 업그레이드 되었는지 수치로 비교한 결과를 살펴보겠습니다.
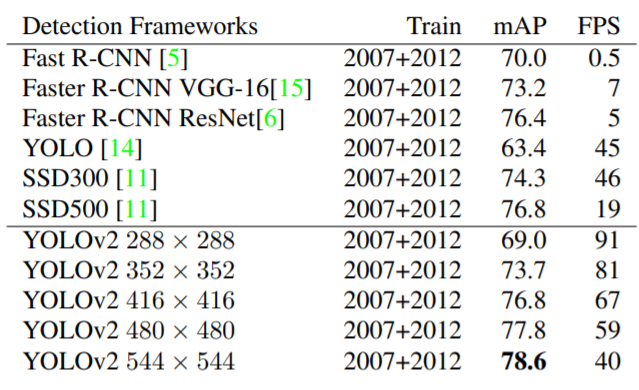
전작인 YOLO v1의 63.6 mAP에 비하여 상당히 발전된 78.6을 기록한 것을 확인할 수 있네요! FPS 속도도 45에서 40으로 한결 더 빨라졌습니다!