
[Review] YOLO v1
[Paper review] YOLO_v1
Object detection에 관한 논문들을 읽어보고자 합니다. 논문 리스트는 시간 순으로 정리되어 있는 깃헙이 있어 이 곳을 참고하여 히스토리를 거슬러 올라가려고 합니다. 너무나 잘 정리가 되어있어 많은 도움을 받고 있습니다.
먼저 가장 궁금했던 YOLO 계열의 논문들을 죽 따라가보며 리뷰해볼까 합니다! 가장 첫 번째 버전인 You Only Look Once: Unified, Real-Time Object Detection, Redmon, Joseph, et al. , Proceedings of the IEEE conference on computer vision and pattern recognition (2016) 부터 출발합니다~!
(본 리뷰의 모든 수식과 그림은 원 논문을 참고했습니다.)
YOLO의 장점
You Only Look Once라는 제목에 걸맞게 YOLO detector가 추구하는 방향은 어느 정도의 정확성을 갖추면서(가장 높은 정확성 x) 다른 detector들보다 훨씬 빠르게 이미지를 판별하는 것입니다. 저자도 YOLO가 “extremly fast”하다며 이를 강조하고 있는데요! 이렇게 빠른 속도가 가능한 이유는 detection model을 일종의 single regression 문제로 단순화 시켰기 때문입니다. YOLO는 주어진 이미지 픽셀을 가지고 bounding box (object를 판별하는 네모 범위)의 위치와 이를 나타내는 class probability 를 single convolution 으로 빠르게 계산합니다. 이 때문에 복잡한 classification pipeline이 필요없으며 YOLO의 계산 속도를 빠르게 만듭니다.
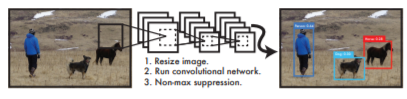
YOLO의 두 번째 장점 은 이미지 픽셀 조합을 전부 다 들여다보기 때문에 robust하면서도 전체적인 모든 object를 다 찾아낼 수 있다는 것입니다.
![]()
위 사진을 보면 YOLO가 전체 이미지 픽셀을 모두 search하여 가장 confidence가 높은 box들을 굵은 표시로 찾아낸 것을 확인할 수 있습니다. 이렇게 모든 pixel 조합들을 탐색할 수 있는 이유는 역시 YOLO가 빠른 속도를 가진 detector이기 때문입니다.
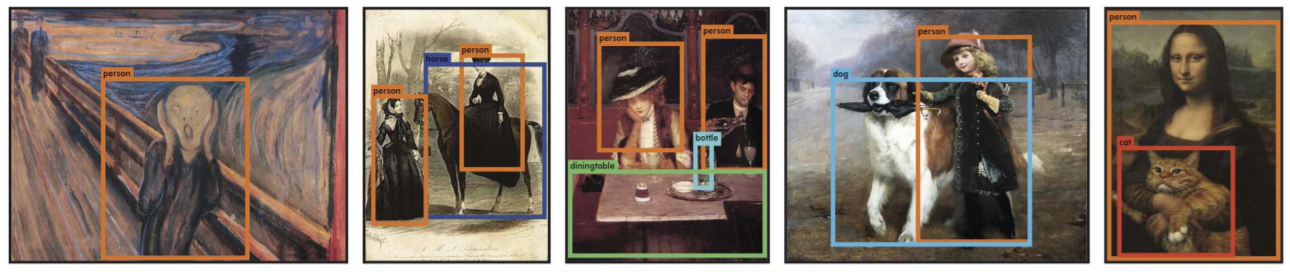
YOLO의 세 번째 장점 은 generalizable representation에 대해 학습한다는 것입니다. 논문 후반부에 제시되는 예술 작품에 대한 detector 비교에서 YOLO는 뛰어난 성능을 보여줍니다. 학습한 데이터셋과 특성이 다른 (사진이 아닌 그림인) 예술 작품들에서도 사물을 잘 잡아낸다는 것은 그만큼 object의 general한 특징을 잘 학습한다는 것을 의미합니다. 저자들은 이러한 YOLO의 장점이 new domain 에서도 어느 정도의 성능을 담보해줄 수 있다고 기대합니다.
YOLO methodology
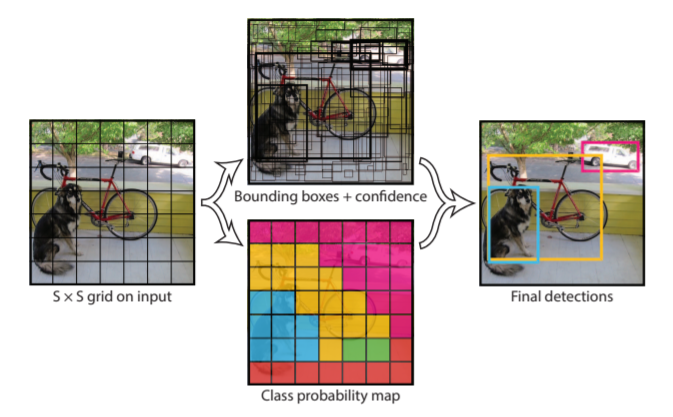
YOLO의 model 매커니즘을 가장 잘 이해할 수 있는 figure입니다. 설명에서 알 수 있듯이 YOLO는 두 가지 도구를 가지고 object detection을 수행합니다. 첫 째, Confidence score가 높은 Bounding box, 둘 째 Class probability가 높은 셀 구역입니다. 먼저 이 두 가지 도구를 갖추기 위해 이미지 픽셀을 $S * S$ 구역으로 grid하게 나누어줍니다. 이 구역들의 전체 조합에서 확률 계산을 통해 두 도구를 갖추는 것입니다.
먼저 각 grid cell은 B개의 Bounding box 를 예측합니다. B개를 선택하는 기준은 confidence score입니다. confidence score는 bounding box가 object를 담고 있는지, 담고 있다면 얼마나 정확하게 담고 있는지를 나타내는 지표입니다. 이는 Confidence score를 계산하는 식을 살펴보면 더 잘 알 수 있습니다.
\[\begin{gathered} \textit{Confidence score} = P(Object) \cdot IOU^{truth}_{pred} \end{gathered}\]$P(object)$ 는 말 그대로 어떤 object를 담고 있을 확률을 의미합니다. 따라서 이 확률이 낮다면 아무리 IOU가 높아도 Confidence score가 높아질 수 없습니다. 일단 Object를 담고 있을 확률이 높다면 얼마나 정확하게 box가 object 주위를 감싸고 있는지를 알아봐야 합니다. $IOU^{truth}_{pred}$ 가 바로 그 부분입니다. 이 두 값의 곱이 높은 bounding box를 찾아줌으로써 우리는 object를 가장 잘 둘러싸고 있는 bounding box를 찾아낼 수 있습니다. YOLO는 bounding box output으로 box의 좌표값인 $x, y, w, h$ 와 confidence score를 가집니다.
두 번째로 각 cell이 어떤 class를 가질 확률이 높은지 class probability map을 그려줍니다. Conditional probability로 어떠한 Object가 주어졌을 때 어떤 Class를 가질 확률이 높은지 찾아주는 map입니다.
\[\begin{gathered} \textit{Class probability} = P(Class_i | Object) \end{gathered}\]모든 grid cell에 전부 위 확률을 구해주며, 이를 통해 각 cell이 어떤 class를 가질 확률이 높은지 알 수 있습니다. 예시 figure를 살펴보면 강아지가 있는 부분은 하늘색, 자전거는 노랑색, 차량 및 배경은 빨간색 등으로 Class probability가 높은 구역끼리 표현된 것을 확인할 수 있습니다.
종합하면 YOLO는 위 두 도구를 이용하여 confidence score가 높은 box들을 선택 한 뒤, 그 box들에 포함된 grid cell들이 어떤 class에 들어갈 확률이 높은지 파악하여 그 class로 detection하는 매커니즘을 가지고 있습니다. 이에 YOLO의 prediction은 $S * S * (B * 5 + C)$ 의 tensor 구조를 갖게 됩니다.($C = classes$)
Network design
그렇다면 이런 매커니즘을 수행하는 Network는 어떤 아키텍처를 가지고 있을까요? 빠른 수행을 요하는 YOLO인만큼 꽤 단순한 구조를 가지고 있습니다. 저자들은 GoogLeNet을 참고하여 24개의 convolutional layer를 가지고 2개의 fully connected layer 가 붙는 구조를 만들었습니다.
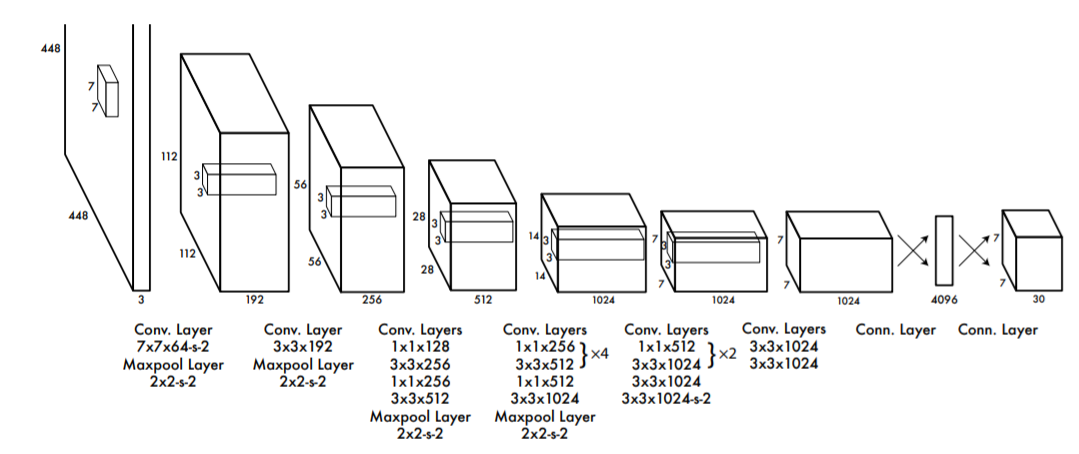
위 구조의 구체적인 layer dimension값은 PASCAL VOC set을 학습하는 $7 * 7 * 30$에 맞추어져 있습니다. Convolutional layer는 ImageNet task에서 pretrain 된 것을 사용했으며 input resolution을 높이기 위해 input size를 imageNet의 두배인 $448 * 448$로 세팅했습니다. 저자들은 정규 YOLO 외에 속도를 매우 빠르게 design한 Fast YOLO도 소개했습니다. Fast YOLO는 convolutional layer를 단 9개만 사용하면서 더 simple하게 network를 design했습니다.
Loss function
YOLO의 train을 담당하는 Loss function에 대해 간단히만 살펴보고자 합니다. 논문에 소개된 Object function은 다음과 같습니다.
\[\begin{gathered} \lambda_{noobj}\sum^{S^2}_i\sum^B_j I^{noobj}_{ij} (C_i-\hat{C_i})^2 + \\ \sum^{S^2}_i I^{obj}_i\sum_{c\in Class}(p_i(c)-\hat{p}_i(c))^2 + \\ \sum^{S^2}_i\sum^B_j I^{obj}_{ij} (C_i-\hat{C_i})^2 + \\ \lambda_{coord}\sum^{S^2}_i\sum^B_j I^{obj}_{ij} [(x_i-\hat{x_i})^2 + (y_i-\hat{y_i})^2] + \\ \lambda_{coord}\sum^{S^2}_i\sum^B_j I^{obj}_{ij} [(\sqrt{w_i}-\sqrt{\hat{w_i}})^2 + (\sqrt{h_i}-\sqrt{\hat{h_i}})^2] \\ \textit{where } \lambda_{noobj} = 0.5, \lambda_{coord} = 5 \end{gathered}\]꽤 길어보이는데요! 하나씩 살펴보겠습니다. 먼저 가장 중요한 Key역할을 하는 Indicator function들에 대해 살펴봐야 합니다. 본문에 $i$는 cell, $j$는 bounding box의 인덱스입니다. 즉, $I^{obj}i$는 해당 cell안에 object의 존재 여부 / $I^{obj}{ij}$는 i번째 cell안의 j번째 bounding box가 prediction하기에 충분히 responsible 한 지에 대한 여부를 나타냅니다. 여기서 responsible 이란 IOU가 가장 높은 bounding box를 나타낼 겁니다. 즉, YOLO의 Loss function은 각 셀과 box들이 object를 담고 있느냐 없느냐에 따라 conditional하게 function의 모양이 달라지는 것입니다.
먼저 cell과 box가 모두 object를 포함하지 못한다고 판단되면 어떻게 될까요? ($I^{noobj}_{ij} = 1$) 첫 번째 term을 제외하고 아래의 모든 term들이 사라지게 됩니다. 즉 가장 간단한 loss function 이 되는 것이죠. 아무래도 중요도가 떨어지기 때문입니다. (object도 포함하지 않은 영역을 굳이 coordinate까지 최적화할 필요는 없겠죠.)
그 다음 단계는 cell은 object를 포함하고 있으나 box는 responsible하지 않은 경우입니다. ($I^{obj}_{i} = 1$) 이 경우, 두 번째 term만이 남게 되죠. 역시 bounding box가 믿음직스럽지 못하기 때문에 굳이 coordinate까지 최적화할 필요가 없습니다.
마지막으로 cell도 object를 포함하고 box도 responsible 한 경우입니다. ($I^{obj}_{ij} = 1$) YOLO가 가장 최적화하고 싶어하고 정확하게 잡아내고 싶어하는 cell과 box일 것입니다. 이에 여러 가지 penalty항들이 추가됩니다. Class($C$)에 대한 정보들, x, y 좌표값과 weight($w$), height($h$)에 해당하는 box의 크기에 대한 부분까지 최적화의 대상이 됩니다. 이러한 Loss function으로 YOLO는 더 완벽한 box를 학습하게 됩니다.
이렇게 conditional한 loss function을 사용함으로써 YOLO는 더 빠른 속도를 가지게 되는 것 같습니다. 굳이 중요하지 않은 부분은 깊이 있게 학습하지 않기 때문이죠. 이러한 특징은 속도 뿐만 아니라 YOLO가 generality한 특성을 갖는데에도 도움을 줄 것으로 생각됩니다.
Experiment Results
이제 실제 dataset에서 다른 detector들과 비교하여 YOLO가 어떤 성능을 나타내주는 지 비교해봅시다.
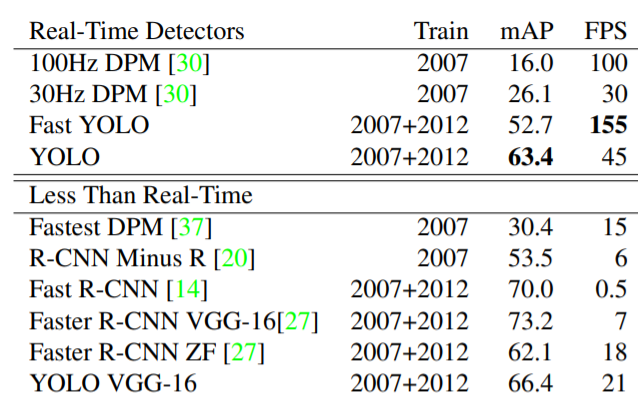
각 detector들 별로 PASCAL VOC 2007, 2012 데이터로 학습했을 때의 성능 평가를 나타낸 표입니다. mAP는 정확성, FPS는 컴퓨팅 속도의 지표입니다. Fast YOLO가 155에 달하는 속도를 보여주며 매우 빠른 detector임을 자랑했습니다. YOLO의 경우 FPS 45를 기록하며 Real-Time detector 중에서도 매우 빠른 속도를 가짐에도 mAP에서 다른 detector들에 비해 그다지 떨어지지 않는 퍼포먼스를 보여줍니다. Detection의 정확도가 정말 높지 않더라도 매우 빠르게 이미지를 인식하자는 YOLO의 방향성에 맞는 결과인 것 같습니다.
Limitation
이런 YOLO에도 한계점이 존재합니다. 먼저 YOLO가 grid cell을 나누어 bounding box를 설정하기 때문에 공간적 constraint를 받을 수 밖에 없습니다. 또한 loss function이 bounding box에 크기에 상관없이 계산되기 때문에 큰 box에서의 작은 error는 무시될 확률이 높은 반면 작은 box에서의 작은 error는 critical하게 반영됩니다. 이러한 두 한계점으로 인해 새와 같은 작은 물체를 detection하는 데 어려움이 있습니다.
마무리
저자들은 (YOLO의 이름에서도 알 수 있듯이) 인간이 살짝 물체를 보아도 그 것이 무엇인지 알아채는 것에 아이디어를 얻어 이 detector를 고안했다고 합니다. 점차 image detection의 활용 범위가 넓어지고 있어 이렇게 빠른 속도에 기반한 detector들이 더 쓰임새가 많아질 것 같습니다. YOLO가 version을 upgrade하면서 얼마나 발전할지 다음 논문에서 살펴봐야겠습니다!