
[Review] YOLO v3
[Paper review] YOLO_v3
YOLO series의 3번째 버전, YOLO v3 입니다. (이전 버전 리뷰: YOLO v1 review, YOLO v2 review)
Object detection에 관련된 여러 competition이나 project를 살펴볼 때 빠짐없이 등장하는 모델이었는데요!
논문도 아주 짧고 굵어서 호다닥 리뷰해보겠습니다.
구성은 이전 v2와 마찬가지로 기존 버전에서 어떤 것을 업데이트 했는지 말하고 있습니다.
Redmon, Joseph, and Ali Farhadi. “Yolov3: An incremental improvement.” arXiv preprint arXiv:1804.02767 (2018)
(본 리뷰의 모든 수식과 그림은 원 논문을 참고했습니다.)
Bounding Box Prediction
이전 YOLO v2에서 Direct location prediction이라는 이름의 소챕터로 다루어졌던 내용의 연장입니다. YOLO v2에서의 내용은 Anchor box의 도입에 따라 restriction이 추가된 \(b_x, b_y, b_w, b_h\)의 좌표를 prediction하는 것이었습니다.
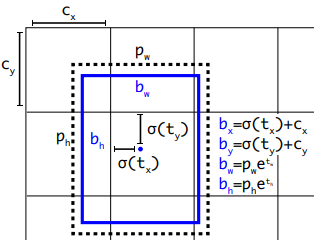
YOLO v3에서도 비슷합니다. 이 때 Coordinate의 update를 위한 gradient로 \(\hat{t_*} - t_*\), 일종의 SSE를 사용한다고 합니다.
(\(b_*\)를 사용하지 않고 t의 값들을 사용하는 이유가 무엇인지 궁금하네요!)
또한 YOLO v3에서는 Objectness score를 계산하여 정확도를 높입니다. Logistic regression을 통해 각각의 Bounding box가 object를 포함할 확률을 예측하는데요. 1이면 ground truth object를 overlap한다고 볼 수 있습니다. 각 Bounding box들 중에서도 IOU가 가장 큰 box 1개만이 실제 object에 할당될 수 있습니다. (대표 박스라고 볼 수 있겠습니다.) Objectness score(아마도 logistic regression의 예측확률?)가 threshold 0.5를 넘었더라도 대표 박스가 되지 못한 개체들의 prediciton은 무시되기 때문에 추후 loss function계산에서 제외됩니다.
Class prediction
YOLO v3에서는 class를 prediction하기 위해 Binary cross-entropy를 class 각각에 대해 적용합니다. 이는 일반적으로 softmax를 적용하는 것과는 다른 것인데요. Softmax function을 사용하는 것보다 개별 확률을 예측해주는 것이 multi-label detection (ex. class가 여자(woman)이면서 사람(Person)인 경우)에서 더 좋은 성능을 가져온다고 합니다.
Darknet-53
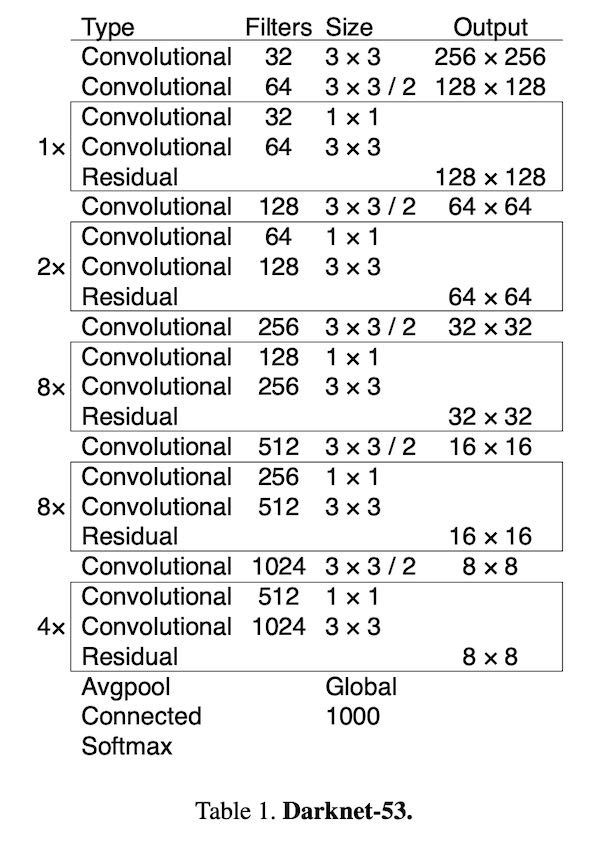
YOLO v2에서 가장 크게 업그레이드 된 파트 중 하나, Darknet-53입니다. 기존 YOLO v2에서는 19개의 convolutional layer를 가진 Darknet 19를 backbone으로 활용했습니다. 하지만 점차적으로 복잡해지고 좋은 성능을 요구하는 추세에 맞추어 convolutional layer를 53개로 늘렸습니다. 이 때, layer가 깊어짐에 따라 diminishing effect 등의 부작용을 방지하기 위해 residual network를 중간 중간 섞어 주었습니다. Residual shortcut connection으로 인해 기존 대비 훨씬 깊어진 Convolutional layer를 가질 수 있게 된 것입니다.
Predictions Across Scales
YOLO v3에서 darknet-53과 더불어 가장 큰 업데이트이지 않을까 생각됩니다. 바로 prediction box의 scale을 3가지로 나누어 예측한다는 것입니다. 아무래도 region based predict에서 출발한 YOLO였기 때문에 항상 scale에 따른 예측 robust를 불안해하고 신경쓰고 있었는데 이 부분에 대한 보완인 것으로 보입니다. 구체적으로 어떻게 진행하는 지 다음의 도식과 함께 살펴보겠습니다.
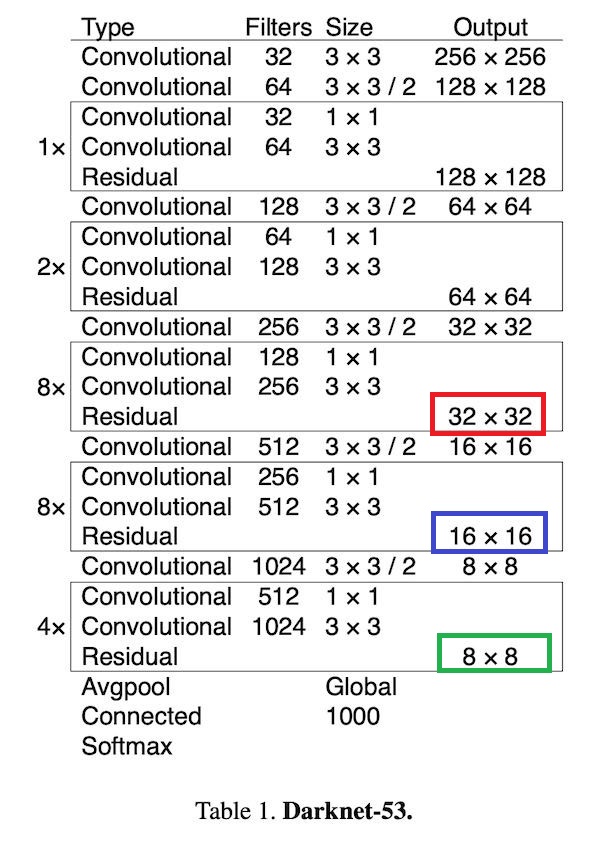
방금 전 살펴본 darknet-53 형태입니다. 빨강, 파랑, 초록의 세 박스를 표시해두었는데요. 이 부분들에서 하나씩 feature map을 뽑아내어 predict을 진행하는 구조입니다. 먼저 빨강 네모에서 32 x 32 feature map을 얻을 수 있습니다. 이를 통해 13 x 13 scale을 가진 box로 predict 하는 것이 가능합니다. (Input size가 416 x 416이므로) 마찬가지로 파란 네모에서는 16 x 16 feature map을 얻을 수 있으며 26 x 26 scale predict이 가능합니다. 마지막으로 초록 네모에서는 8 x 8 feature map을 활용하여 52 x 52 scale predict이 가능하겠네요! 총 13, 26, 52 세 가지 scale의 박스를 통해 object를 detect할 수 있습니다.
(의문 1: YOLO v2 논문에서 Multi-Scale Training이라는 part로 YOLO는 batch마다 input size를 바꿔가며 train을 진행한다고 배웠습니다. 위의 scale들은 input size, 여기서는 416 x 416이 바뀌면 자연스럽게 바뀌게 되는 값들인데 그렇다면 predict box의 scale이 가변하는 것이 궁금하네요! ㅎㅎ)
이 때, 각 scale의 prediction값들은 독립적으로 진행되는 것이 아니라 앞 선 결과를 뒤 scale에 반영해주는 식으로 연결되어 있습니다. Ethan Yanjia Li님의 블로그에 이를 잘 나타내주는 diagram이 있어 가져왔습니다.
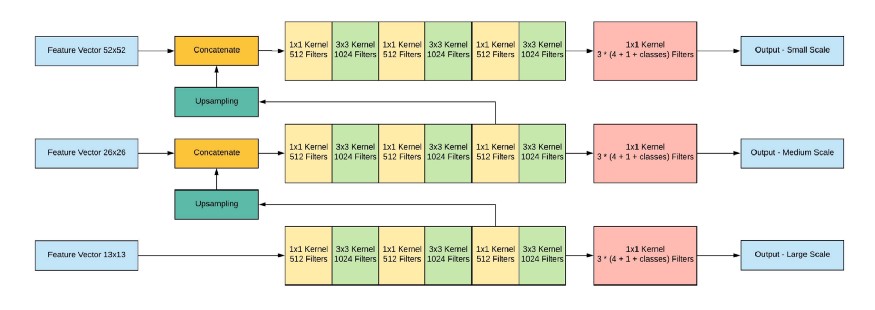
위 diagram을 살펴보시면 먼저 13 x 13 feature vector가 output산출을 위해 Fully Convolutional Network를 탈 때, 중간에 그 결과를 뽑아내어 upsample해줍니다. (x2배) 이 vector를 상위 scale, 즉, 26 x 26 feature vector와 concatenate해서 다음 FCN을 진행합니다. 마지막 52 x 52도 마찬가지입니다. 이를 통해 meaningful semantic information과 finer-grained information을 반영할 수 있다고 저자는 밝히고 있습니다.
Output 형태는 N x N x [3 * (4 + 1 + 80)]입니다. N은 image의 pixel 정보이고 3은 사용할 box의 수입니다. (본 논문에서는 COCO dataset에 대해 3개의 box를 사용하고 있습니다.) 4는 box의 offset, 1은 objectness prediction, 80은 class predict 정보입니다. 각각의 scale box에 대해서 총 3개의 output을 얻을 수 있습니다.
Experiment Results
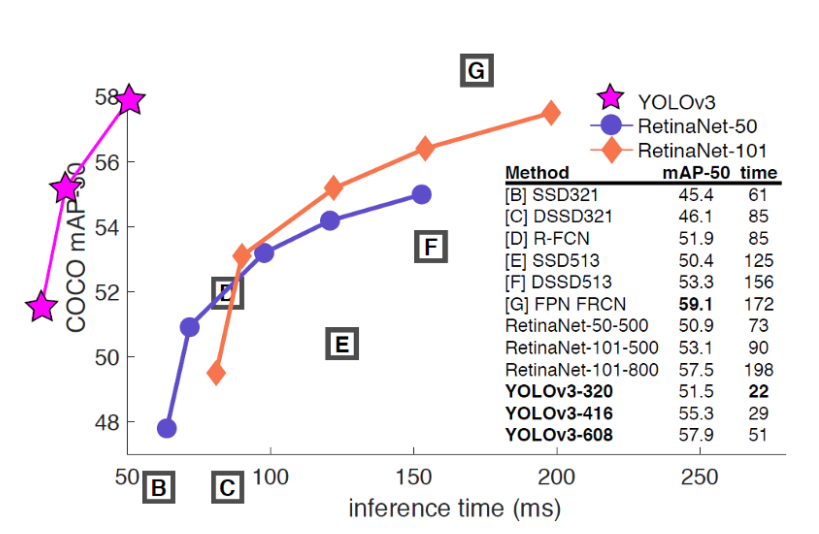
YOLO v3의 result결과입니다. (plot을 상당히 개성적으로 그리셨습니다 ㅎㅎ) YOLO v3는 mAP 50일 때 가장 좋은 결과를 보여줍니다. (cf. overall mAP 등으로 측정했을 때는 정확도가 조금 떨어지는 것을 확인할 수 있는데요. 저자는 어차피 인간이 object를 판별할 때도 mAP 30이나 50이나 큰 차이를 느끼지 못한다고 언급하며 mAP 50에서의 성능이 좋다면 상관없다고 밝히고 있습니다.) 여전히 타 알고리즘에 비해 현저히 빠른 속도와 준수한 정확도를 보여주는 것을 확인할 수 있습니다.
(의문 2: result plot을 보면 YOLOv3-320, 416, 608로 되어있는 것을 확인할 수 있는데요. Input size의 크기를 의미하는 것 같습니다. 앞 서 의문 1과 연계하여 320과 608은 predict box scale이 달라진 걸까요..?)