
Personality Detection from Text in Korean
Personality Detection from Text in Korean
이번 포스팅은 이전 포스팅에서 다루었던 논문의 architecture를 실제로 적용해보는 프로젝트를 진행한 과정을 소개하겠습니다. 수업에서 간단한 활용 사례를 보이기 위해 진행한 예제로 모델의 성능 등은 우수하지 못함을 알려드립니다 (ㅠㅠ) 우선 이전 포스팅에서 다룬 논문은 간략하게 설명하자면 주어진 Text에서 저자의 Personality를 detection하는 것입니다.
참조 논문의 모델은 영어 text를 기반으로 작성되어 있지만 이번 예제에서는 더 직관적인 이해를 위해서 한국어 text에서의 감성 분석을 진행해보고자 합니다. 한국어 text로 변경하면서 참조 논문과 약간 달라진 수정 사항들을 정리해보았습니다.
- Text dataset이 essay에서 news article로 변경
- 한국어 word2vec embedding 사용
- 기존의 5-level classification에서 Positive personality만을 활용한 1-level classification으로 변경
- Document level Mairesse vector 미 삽입
한가지씩 살펴보겠습니다. 먼저 text dataset을 기존 논문의 essay에서 비교적 구하기 쉬운 news article로 바꿨습니다. 네이버 스포츠 뉴스에서 크롤링한 기사들인데요, 자세한 내용은 다음 챕터에서 설명하겠습니다. 두 번째로는 한국어 데이터 분석이니 word embedding을 한국어 word2vec으로 바꿨습니다. 세 번째로 참조 논문은 저자의 특성을 5가지로 구분하여 classification하고 있는데요! 레이블을 달기 어렵기도 하고 다른 특성들은 구분하기 어렵다고 판단하여 positive만을 활용한 간단한 분류 문제로 재 정의했습니다. positive 특성도 뉴스 특성에 따라 다르게 정의할텐데, 이 부분도 다음 파트에서 다루겠습니다. 마지막으로 Mairesse vector를 삭제했습니다. 본 vector는 document level의 essay특성을 더 잘 잡아주기 위한 조정 단계인데, dataset이 news로 바뀐만큼 불필요하다고 판단했습니다. (영어 text를 위한 조정이기도 하구요!) 그렇다면 데이터의 형태부터 소개하도록 하겠습니다.
데이터 소개
앞서 소개해드린대로 데이터는 News article입니다. 뉴스 기사를 선택한 이유는 네이버에서 비교적 쉽게 크롤링할 수 있기 때문입니다. 그런데 크롤링하고 보니 뉴스 기사의 저자가 인성 특성을 보인다는 것이 말이 안된다는 것을 깨달았습니다… 그래서 저자의 특성이 아닌 기사 자체의 특성으로 분류 문제를 재 정의했습니다! (본 논문에서 너무 바뀌는 것이 아닌가 하는..하하)
기사의 긍정적인 특성을 빠르고 쉽게 캐치해야 되기 때문에 (제가 직접 label을 달아줄 것이기 때문입니다..) 이기고 지는 것이 명확한 스포츠 뉴스를 타겟으로 삼았습니다. 제가 관심을 많이 가지고 있는 야구에서, 제가 응원하는 팀인 기아 타이거즈를 키워드로 뉴스 기사들을 모았습니다. 2019 시즌의 기사들을 대상으로 하였고 대략 일주일에 100여개씩, 한달 동안 총 550여개의 기사들을 모을 수 있었습니다.
레이블을 다는 방법은 간단합니다! 기사의 내용을 읽고 기아 타이거즈가 승리하였거나 기아 타이거즈 팀에 긍정적인 내용에 해당하면 1, 반대의 경우 0을 부여했습니다. (엄청난 팬심이 가미된 레이블링입니다 ㅎㅎ)
완성된 데이터 셋의 모습은 다음과 같습니다.

데이터 전처리
완성된 dataset을 tokenize해줍니다! 또한 #, &, *과 같은 분석에 큰 도움을 주지 않는 (뉴스 기사에 특히 많은) 특수 문자들을 제거해줍니다.
이제 이 데이터를 한국어 버전 word2vec embedding matrix를 사용하여 vectorize해주겠습니다. 이제 이로써 모델에 들어갈 input dataset이 완성되었습니다!
모델 결과
모델의 architecture는 참조 논문의 형태와 동일합니다. 간단하게 리뷰하자면 다음과 같습니다.
| No. | Layer | Level |
|---|---|---|
| 1 | Input layer | Word |
| 2 | Convolution layer | Word |
| 3 | Max-pooling layer | Word |
| 4 | Concatenation layer | Sentence |
| 5 | 1-max pooling layer | Document |
| 6 | Fully connected layer | Document |
| 7 | Output layer | Document |
간단하게 Accuracy와 Objective function(Negative log likelihood)의 Loss를 기준으로 CV과정을 살펴보겠습니다. Dataset이 비교적 작기 때문에 5:1의 비율로 train / valid set을 나누고 진행했습니다.
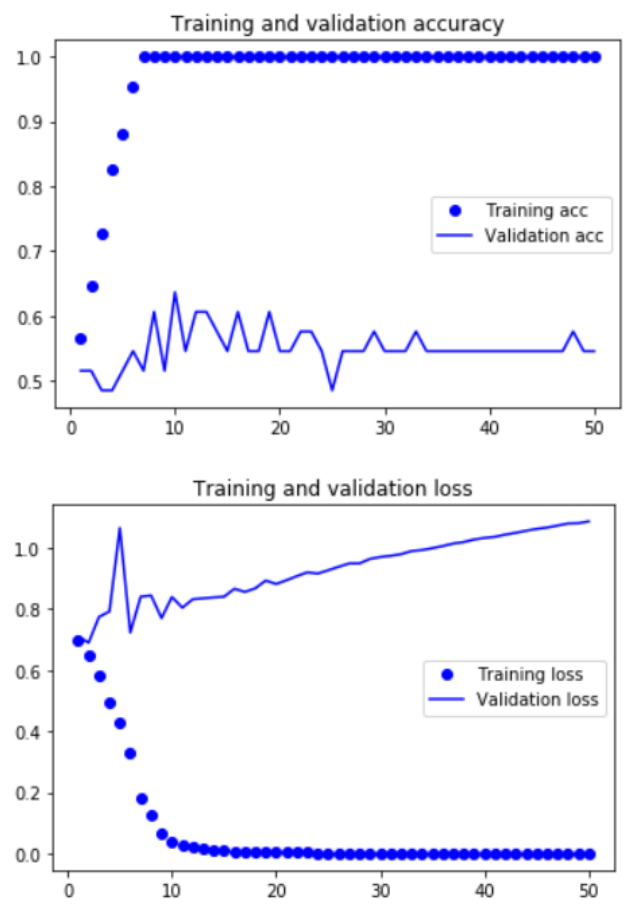
첫 50 epoch을 진행한 결과입니다. 처음부터 끝까지 overfitting의 향기가 진하게 납니다. 데이터가 비교적 간단하기 때문에 벌어지는 현상 같은데요. Layer의 수정이 조금은 필요하지 않나 생각했습니다. 이에 Dropout layer를 추가하고 epoch도 조금 줄여서 data에 customizing을 시켜주었습니다!
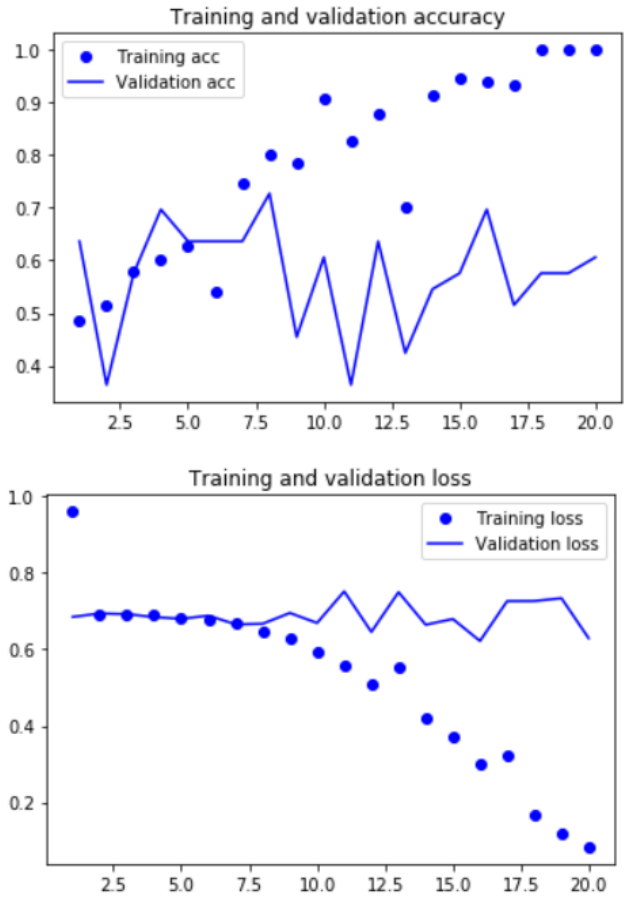
이전 결과보다는 비교적 괜찮아졌습니다! 대략 7~10 정도의 epoch에서 모델을 끊어주는 것이 좋아보입니다. Accuracy는 대략 0.73정도의 퍼포먼스를 보여주는데요. 적용해보는 예제의 성격인만큼 모델 업그레이드는 이 정도만 하도록 하겠습니다! (후다닥)
시사점
아무래도 Accuracy가 높지 않다보니 개운하지 못한 느낌입니다 ㅎㅎ. Essay에서 News로 데이터의 성격이 바뀐 부분도 있고 (기사의 특성을 제가 잘 처리하지 못한 것 같습니다) Label을 제가 직접 달았다보니 모델이 학습하기 애매한 부분 (분석자의 직관이 반영된 부분)이 많이 포함되었기 때문이라고 보입니다.
예제를 진행하면서 아무래도 2017년 논문이다보니 딥러닝 모델의 architecture가 조금 단순하다는 생각을 했습니다. 요즘 유행하는 발전된 모델들을 적용한다면 더 좋은 성능을 보여줄 수 있지 않을까 생각합니다.
본 프로젝트는 논문 리뷰와 실전 적용을 해본 것에 만족하고 마무리하도록 하겠습니다~!