
Deep Learning-Based Document Modeling for Personality Detection from Text
Deep Learning-Based Personality Detection from Text
이번 포스팅은 CNN을 활용하여 Text 저자의 Personality를 판별하는 감성 분석 논문에 대해 리뷰해보겠습니다.
Deep Learning-Based Document Modeling for Personality Detection from Text (N. Majumder, S. Poria and A. Gelbukh and E. Cambria) 의 논문을 기초로 리뷰하였으며 해당 논문은 2017년에 IEEE Computer Society에 발표된 논문입니다. 본 포스팅에서 논문에서 소개하는 프로세스와 CNN 아키텍처에 대해 살펴보고 다음 포스팅에서는 이 논문을 활용하여 실제 실습 프로젝트를 진행해보겠습니다.
Objective
본 논문의 목표는 주어진 Text에서 저자의 Personality를 detection하는 것입니다. 일종의 감성 분석이라고 볼 수 있는데요. 논문의 저자는 찾아내고자 하는 특성으로 5가지 Personality traits를 제안합니다. 따라서 5-level classification 문제라고 정의할 수 있습니다.
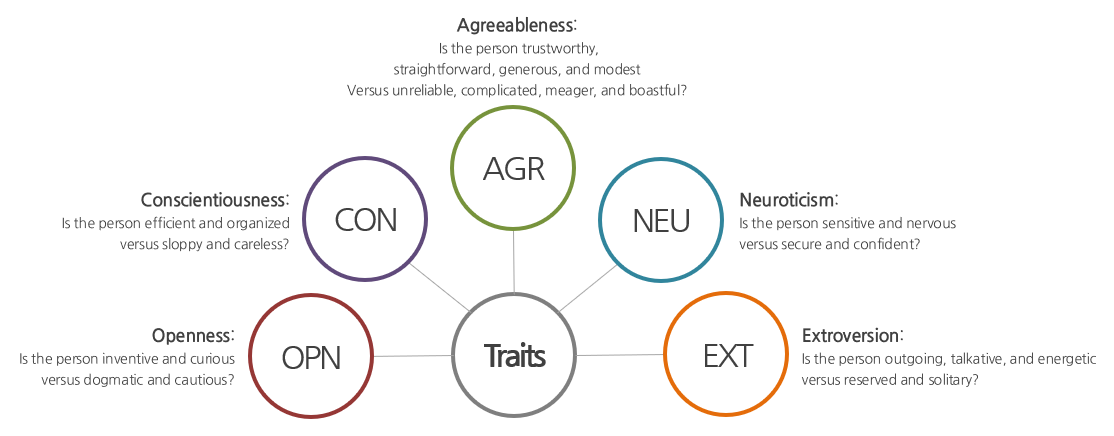
Process
Classification을 진행하는 절차는 다음과 같습니다. 하나하나 차근차근 살펴보겠습니다.
1. Data Input
분석을 진행하기 위해 Text data를 확보합니다. 여기서 중요한 것은 각 Text data마다 5 class에 대한 label이 붙어있어야 한다는 것입니다. 이는 뒤에서 소개할 모델링이 Supervised learning으로 구성되어 있기 때문인데, 본 논문의 아쉬운 점 중 하나라고 생각합니다. (새로운 text data를 구할 때마다 5가지 특성에 대한 class를 새로 달아주어야 하기 때문이죠.) 저자는 James Pennebaker and Laura King’s stream-of-consciousness essay dataset을 사용하였고 2,467개의 essay data가 포함되어 있습니다.
2. Preprocessing & Filtering
Data를 받고나면 전처리 과정을 거쳐서 model에 넣어주어야 합니다. 본 방법론은 단어 수준의 vector에서부터 패턴을 파악하여 전체 글의 특성을 파악하는 bottom-up 분석 방법이기 때문에 text data를 word level로 분해해주어야 합니다. 주로 ., ?, ! 등의 문장부호를 기준으로 하거나 띄어쓰기를 기준으로 분해해줍니다.
이후에는 Filtering단계를 거칩니다. 저자는 생성된 단어 벡터들 중 emotion이 포함되지 않은 단어는 분석에서 제외합니다. Emotion이 포함된 단어 벡터를 저자는 “Emotionally Charged Vector”라고 합니다. 이러한 ECV를 찾기 위해서 NRC Emotion Lexicon을 참고합니다. Lexicon에는 10개의 emotion으로 tagging된 6,468개의 단어가 포함되어 있습니다. 저자는 단어 벡터들 중 이 lexicon에 포함되지 않은 단어들은 분석 대상에서 제거합니다. 이러한 Filtering 작업은 모델의 성능을 높혀준다고 밝혀져 있습니다.
3. Modeling
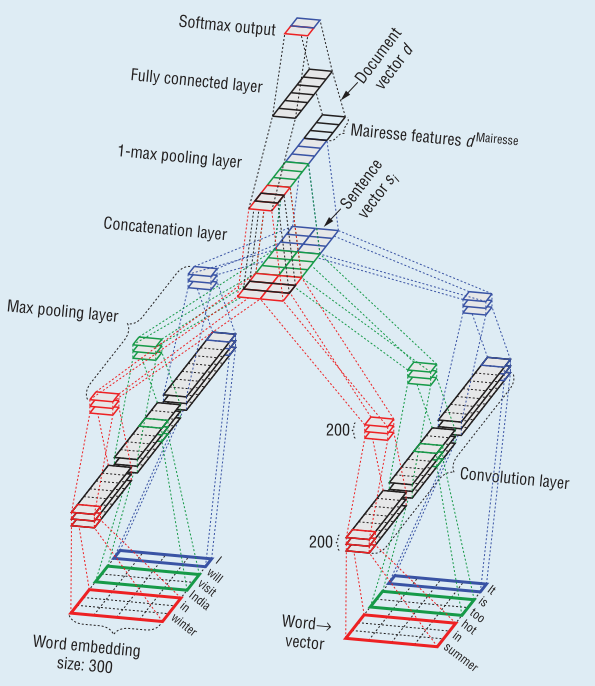
이제 본격적으로 CNN Model의 Architecture에 대해 살펴보겠습니다.
Model에서 중요한 layer는 다음과 같습니다.
- Input layer
- Convolution layer
- Max-pooling layer
- Concatenation layer
- 1-max pooling layer
- Fully connected layer
- Output layer
이 중에서 Input, Convolution, Max-pooling layer는 Word-level에서 분석이 진행되고 Concatenation layer는 Sentence-level에서 진행됩니다. 마지막 1-max pooling, Fully connected, Output layer는 Document-level에서 최종적으로 classification을 수행합니다. 이제 각각에 대해 알아보도록 하겠습니다.
- Input layer Input layer에 투입되는 text data는 4-dimensional array로 구성됩니다.
여기서 S, W는 단어와 문장의 최대값으로 표현되는 데, 이보다 적은 단어 혹은 문장을 가진 벡터의 경우 padding을 통해 채워줍니다. 또한 단어들의 관계에 대한 word representation이 이루어져야 하므로 embedding space를 활용하게 되는 데 이 때의 dimension이 E로 표현됩니다. 본 논문에서는 구글의 word2vec을 사용하므로 E는 300이 되겠습니다.
- Convolution layer Convolution layer에서는 n-gram filter로 word vector의 feature map을 생성합니다. 본 논문에서는 uni, bi, trigram filter 3가지 종류를 사용하고, 각 filter마다 200개씩의 개수를 가지고 있습니다.
- Max pooling layer 각 Feature map의 대표 특성만을 추출하면서 down-sizing 해주기 위해 max pooling layer를 거칩니다.
- Concatenation layer 지금까지 word-level에서의 feature 추출 작업을 진행했습니다. 이를 결합해서 sentence-level에 해당하는 vector를 생성해야 합니다. Concatenation layer에서는 max pooling을 거친 feature vector를 flatten한 뒤 결합하여 sentence-level vector를 만듭니다.
- 1-max pooling layer 이제 각 sentence vector들의 최대 특성을 추출하여 document-level의 vector를 생성해줍니다.
이 때 본 논문에서는 document자체의 특성에 더하여 $\textit{Mairesse}$ (2007)의 document feature를 추가해줍니다. 이 벡터는 document의 feature를 detection하는 데 도움을 주는 역할입니다. 총 84개의 feature를 포함하고 있습니다. 따라서 이를 모두 합쳐 classification에 넣을 vector를 생성합니다.
\[\begin{gathered} d^{concat} = (d^{network}, d^{Mairesse}) \in \Re^{684} \end{gathered}\]- Fully connected & Output layer 구해진 최종 document vector를 사용하여 Classification할 Personality에 해당하는지 아닌지 softmax function을 활용하여 확률을 예측합니다.
여기까지 아키텍처를 구성하는 7가지의 layer들을 살펴보았습니다. 본 모델에 train이 필요한 부분은 총 3가지 layer입니다. Convolution layer에서의 word filter, Fully connectec layer에서의 weight와 bias, Softmax layer에서의 weight, bias이 이에 해당합니다. 저자는 이 파라미터들을 Negative log likelihood를 loss function으로 하여 Ada delta method로 학습시키고 있습니다.
여기까지 논문의 리뷰를 마치고 다음 포스팅에서 본 모델을 활용한 기사 분류 프로젝트를 실습해보겠습니다!