
[Kaggle] Walmart SaleType Classification
Kaggle Study #1. - Walmart SaleType Classification
이번 포스팅에서 다룰 Kaggle competition은 Walmart SaleType Classification입니다. Walmart에서 제공되는 고객들의 구매이력 data를 바탕으로 해당 고객의 구매타입을 예측해보는 competition입니다. 우선 dataset의 기본적인 형태부터 살펴보겠습니다.
import pandas as pd
train = pd.read_csv("./train.csv")
train.head()
| TripType | VisitNumber | Weekday | Upc | ScanCount | DepartmentDescription | FinelineNumber | |
|---|---|---|---|---|---|---|---|
| 0 | 999 | 5 | Friday | 6.811315e+10 | -1 | FINANCIAL SERVICES | 1000.0 |
| 1 | 30 | 7 | Friday | 6.053882e+10 | 1 | SHOES | 8931.0 |
| 2 | 30 | 7 | Friday | 7.410811e+09 | 1 | PERSONAL CARE | 4504.0 |
| 3 | 26 | 8 | Friday | 2.238404e+09 | 2 | PAINT AND ACCESSORIES | 3565.0 |
| 4 | 26 | 8 | Friday | 2.006614e+09 | 2 | PAINT AND ACCESSORIES | 1017.0 |
print("train set의 shape은", train.shape, "/ test set의 shape은", test.shape)
train set의 shape은 (647054, 7) / test set의 shape은 (653646, 6)
Dataset에는 총 7개의 변수가 있으며, 이 중 TripType이 우리가 맞추어야할 구매 타입 변수입니다. Train과 Test set에 약 65만 건의 구매 정보가 포함되어 있습니다. 이제 이 데이터의 특징에 대해 살펴보겠습니다.
Data EDA
TripType
Competition description을 살펴보면 TripType변수의 999 값은 “기타” 항목입니다. plot의 가독성을 위해 이 값을 -1로 변경한 뒤 살펴보겠습니다.
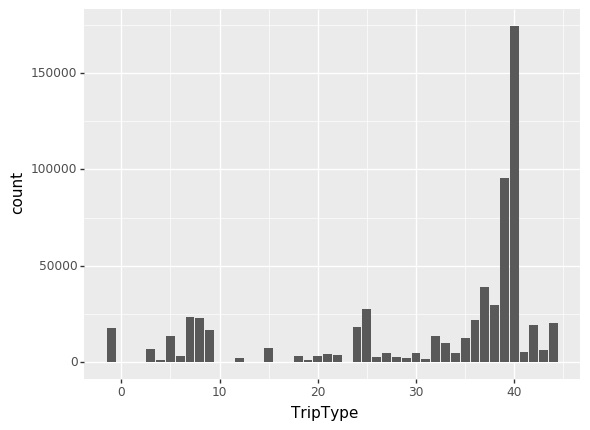
Type값이 0~44까지 존재하고 있음을 알 수 있습니다. 상당히 많은 multi-label classification 문제 입니다. 또 한가지 주목할만한 특징은 많은 타입들 중 39와 40번 타입이 눈에 띄게 많다는 점입니다. 특히 40번 type은 굉장히 많은 빈도를 보여줍니다. 따라서 이 두 가지 type에 대한 특징을 잘 잡아내는 것이 중요할 것으로 판단됩니다.
Weekday
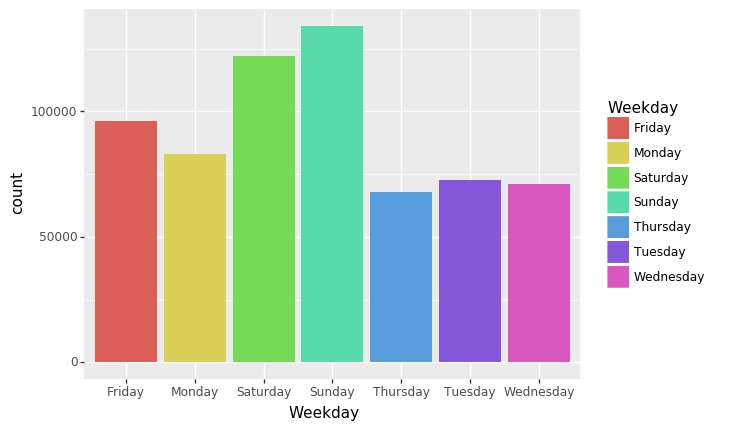
Weekday변수는 물건을 구매한 요일에 대한 정보입니다. 아무래도 휴일인 금, 토, 일에 대한 정보가 많은 것이 확인됩니다. 평일과 주말로 구분하여 분석하는 것도 좋은 방법일 것 같습니다.
Weekday변수는 물건을 구매한 요일에 대한 정보입니다. 아무래도 휴일인 금, 토, 일에 대한 정보가 많은 것이 확인됩니다. 평일과 주말로 구분하여 분석하는 것도 좋은 방법일 것 같습니다.
ScanCount
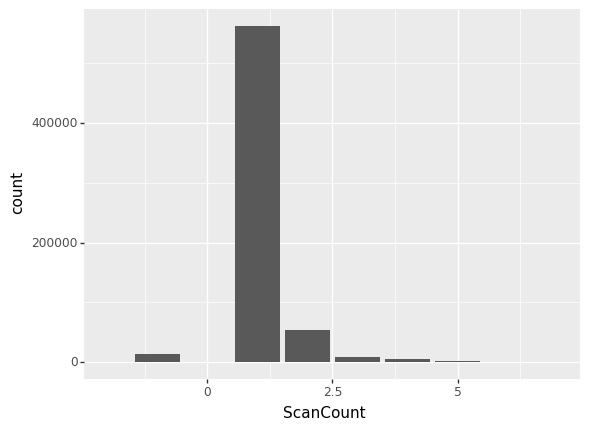
ScanCount 변수는 고객이 구입한 물건의 개수에 관한 정보입니다. 주로 1개의 물건을 구입하는 고객이 많은 것을 확인할 수 있습니다. 최대 많은 물품을 구입한 개수는 5개입니다. -1값은 고객이 물건을 “반품” 처리 하는 경우입니다. 그 수가 많지는 않지만 특수한 Type을 구분하는 데 도움이 될 수 있을 것 같습니다. 이에 어떤 품목이 가장 많이 반품되는지 알아봤습니다.
train[train['ScanCount']==-1]["DepartmentDescription"].value_counts().head(10)
FINANCIAL SERVICES 1138
LADIESWEAR 786
PRODUCE 687
PERSONAL CARE 624
MENS WEAR 618
DSD GROCERY 599
GROCERY DRY GOODS 524
PHARMACY OTC 439
ELECTRONICS 436
BEAUTY 426
Name: DepartmentDescription, dtype: int64
반품이 가장 많은 상위 10개 품목을 뽑았습니다. 금융 서비스가 가장 취소가 많은 것으로 나타납니다. 또한 의류, 약품 같은 생필품의 반품이 가장 많은 것으로 보입니다.
UPC, DepartmentDescription, FinelineNumber
UPC와 DepartmentDescription, FinelineNumber 이 3가지 변수는 한꺼번에 살펴보겠습니다. 그 이유는 첫 째, 전체 data set에서 결측값이 존재하는 변수들이기 때문입니다. 둘 째, UPC와 FinelineNumber변수는 유사도가 높습니다. 먼저 이들의 결측값에 대해 살펴보겠습니다.
train.isnull().sum()
VisitNumber 0
Weekday 0
Upc 3986
ScanCount 0
DepartmentDescription 1328
FinelineNumber 3986
dtype: int64
UPC와 FinelineNumber는 정확히 동일한 결측값의 수를 가집니다. 두 변수는 모두 Walmart에서 고유하게 부여한 상품에 대한 정보인데, 결측값의 추이로 보아 동일한 정보를 담고 있는 것으로 보여집니다. 따라서 추후 분석에서는 두 변수를 모두 사용하지 않고 FinelineNumber만 이용하겠습니다. (FinelineNumber를 선택한 이유는 UPC에 비해 자료의 값이 더 직관적으로 표현되어 있기 때문입니다.) 또한 DepartmentDescription 1,328개 변수도 FinelineNumber Missing case에 포함됩니다.
| TripType | VisitNumber | Weekday | Upc | ScanCount | DepartmentDescription | FinelineNumber | |
|---|---|---|---|---|---|---|---|
| 25 | 26 | 8 | Friday | NaN | 1 | NaN | NaN |
| 548 | 27 | 259 | Friday | NaN | 3 | NaN | NaN |
| 549 | 27 | 259 | Friday | NaN | 1 | NaN | NaN |
| 959 | -1 | 409 | Friday | NaN | -1 | NaN | NaN |
| 1116 | 39 | 479 | Friday | NaN | 1 | NaN | NaN |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 643137 | 41 | 190408 | Sunday | NaN | 1 | NaN | NaN |
| 643991 | 44 | 190651 | Sunday | NaN | 1 | NaN | NaN |
| 645990 | 44 | 191080 | Sunday | NaN | -1 | NaN | NaN |
| 645991 | 44 | 191080 | Sunday | NaN | 1 | NaN | NaN |
| 645992 | 44 | 191080 | Sunday | NaN | 1 | NaN | NaN |
3986 rows × 7 columns
그렇다면 FinelineNumber의 값이 Missing이지만 DepartmentDescription의 값이 Not Missing인 case는 어떤 것일까요?
train[(train['FinelineNumber'].isnull()) & (train['DepartmentDescription'].notnull())]['DepartmentDescription'].value_counts()
PHARMACY RX 2768
Name: DepartmentDescription, dtype: int64
PHARMACY RX 라는 품목이었습니다. 단일 품목만이 조회되는 것으로 보아 해당 품목에 대한 FinelineNumber 변수 입력 처리에 어떤 문제가 있었던 것으로 보여집니다.
Base-line Model
우선 가장 간단하게 base-line model을 만들어서 성능을 체크해보겠습니다. Base-line model이니 만큼 가장 간단하게 building하여 성능의 바로미터로 삼겠습니다.
먼저 EDA를 통해 얻은 정보를 바탕으로 데이터 전처리 과정을 거쳐봅니다.
- UPC 변수 제거
- FinelineNumber 변수 결측값 제거
- Weekday변수: 금토일 = 1, 평일 = 0 으로 범주화
- 문자형 변수 DepartmentDescription 제거
- VisitNumber 기준 중복 행 제거
최대한 간단하게 model을 construct하는 것이 목적이므로 정보의 손실을 감수하고 과감히 변수들을 제거하였습니다. Building한 model의 spec을 살펴보겠습니다.
from keras import layers
from keras import models
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(x_train.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(38, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
return model
Keras를 사용하여 Deep Learning 모델을 구축하였으며 3개의 층을 쌓았습니다. rsmprop optimizer를 사용하고 categorical_crossentropy를 loss function으로 사용하였습니다. Metric은 Customize를 통해 build-up할 수 있으나 간단하게 accuracy를 사용하였습니다.
3-fold로 모델을 학습한 결과 Kaggle leader보드 기준 2.36 의 score를 기록했습니다.
Advanced Model with Feature Engineering
다음으로 Feature engineering을 거친 보다 발전된 model을 만들어보도록 하겠습니다. Department Description변수와 FinelineNumber 변수를 기준으로 파생변수를 생성하는 작업을 진행해 보겠습니다.
DepartmentDescription 파생변수
해당 작업은 Coursera: Learning from the Top Kagglers 강의를 참고하였음을 밝힙니다.
앞서 base-line model에서는 DepartmentDescription 변수를 제거하고 분석을 진행했습니다. 그 이유는 Visit Number당 중복 정보가 존재하기 때문이었습니다. 이 것이 어떤 점이 문제인지 살펴보겠습니다. 먼저 주어진 data는 구매이력 데이터입니다. 즉, VisitNumber는 고객의 ID이며 VisitNumber 하나당 구매 물품 정보들이 중복되어 들어 있습니다. 예를 들어, 다음과 같은 사례를 살펴보겠습니다.
train[train["VisitNumber"]==19]
| TripType | VisitNumber | Weekday | Upc | ScanCount | DepartmentDescription | FinelineNumber | |
|---|---|---|---|---|---|---|---|
| 55 | 42 | 19 | Friday | 7.675336e+09 | 1 | IMPULSE MERCHANDISE | 8904.0 |
| 56 | 42 | 19 | Friday | 6.115665e+10 | 1 | JEWELRY AND SUNGLASSES | 556.0 |
| 57 | 42 | 19 | Friday | 8.874396e+10 | 1 | MENS WEAR | 144.0 |
| 58 | 42 | 19 | Friday | 6.926568e+11 | 1 | FABRICS AND CRAFTS | 397.0 |
| 59 | 42 | 19 | Friday | 7.675336e+09 | 1 | IMPULSE MERCHANDISE | 8904.0 |
| 60 | 42 | 19 | Friday | 6.953344e+11 | 1 | ACCESSORIES | 122.0 |
| 61 | 42 | 19 | Friday | 8.853064e+10 | 1 | MENS WEAR | 5201.0 |
| 62 | 42 | 19 | Friday | 8.830961e+10 | 1 | MENS WEAR | 5661.0 |
| 63 | 42 | 19 | Friday | 3.181070e+09 | 1 | HOME MANAGEMENT | 8124.0 |
위 자료는 VisitNumber가 19인 고객의 정보만을 따로 추려낸 것입니다. 자료를 살펴보면 19번 고객이 같은 날에 총 9개의 품목을 구매하였음을 확인할 수 있습니다. DepartmentDescription 변수를 보면 다양한 품목들을 구매했습니다. 하지만 이 모든 행의 TripType이 동일하게 42로 규정되어 있습니다. 즉, Walmart 측에서는 이 9개 품목의 정보를 전부 반영하여 (동일한 날의 구매 정보를 모두 반영하여) 고객의 구매 Type을 정하고 있음을 알 수 있습니다. 따라서 최종 모델에 VisitNumber를 기준으로 중복제거를 할 시 나머지 품목들의 정보가 모두 사라지게 되어 정확한 분석이 불가능해지게 됩니다.
따라서 모든 품목에 대한 정보를 반영하는 작업을 거칠 것입니다. 그 방법은 VisitNumber를 기준으로 DepartmentDescription 정보를 횡으로 늘어 놓는 것입니다. 다음의 예시를 보면 이해가 쉽습니다.
| VisitNumber | 1-HR PHOTO | ACCESSORIES | AUTOMOTIVE | BAKERY | BATH AND SHOWER | BEAUTY | BEDDING | |
|---|---|---|---|---|---|---|---|---|
| 0 | 5 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 7 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 8 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 9 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 10 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 94242 | 191343 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 94243 | 191344 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 1.0 | 0.0 |
| 94244 | 191345 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 94245 | 191346 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 94246 | 191347 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
DepartmentDescription 변수에 해당하는 모든 값들을 새로운 변수로 추가합니다. 이 후 해당 품목이 있으면 1, 없으면 0을 반환하는 one-hot encoding을 통해 변수 정보를 추가해주면 됩니다.
이 방법은 수 많은 0,1 변수들을 생성하게 되어, Sparse data가 갖는 문제를 야기할 가능성이 높습니다. 일단 변수를 생성하고 분석을 진행해본 뒤 추가 논의 해보겠습니다.
FinelineNumber 파생변수
FinelineNumber 또한 DepartmentDescription과 동일한 문제를 갖고 있습니다. VisitNumber별로 정보가 중복된다는 것인데요. 이를 해결하기 위해 두 가지 파생 변수를 만들어보고자 합니다. 첫 째, FinelineNumber의 Count를 활용하는 변수, 둘 째, FinelineNumber의 CountSum을 활용하는 방법입니다.
-
FinelineNumber의 Count값을 활용
FinelineNumber는 0~2,000까지 다양한 값을 갖습니다. 하지만 품목 별로 고객들이 자주 구매하는 품목, 자주 구매하지 않는 품목으로 나뉩니다. 따라서 각 FinelineNumber들을 Count값으로 변환한 뒤, VisitNumber를 기준으로 그 값을 평균내어 변수로 활용해보겠습니다. 이 변수를 통해 고객이 보편적인 성향을 갖는 타입인지, 마이너한 품목을 즐겨 찾는 고객인지를 살펴볼 수 있을 겁니다.
먼저 FinlineNumber 값의 Count 값을 구해봅니다.
FineLineCount = train[['VisitNumber','FinelineNumber']].groupby('FinelineNumber').count()VisitNumber FinelineNumber 0.0 3837 1.0 461 2.0 224 3.0 94 4.0 187 ... ... 9974.0 54 9975.0 28 9991.0 1 9997.0 50 9998.0 411 5195 rows × 1 columns
이제 이 값을 dataset에 반영하여 VisitNumber를 기준으로 평균낸 변수를 구해보겠습니다.
| TripType | VisitNumber | Weekday | Upc | ScanCount | DepartmentDescription | FineLineCount | |
|---|---|---|---|---|---|---|---|
| 0 | 999 | 5 | Friday | 6.811315e+10 | -1 | FINANCIAL SERVICES | 836.000000 |
| 1 | 30 | 7 | Friday | 6.053882e+10 | 1 | SHOES | 98.500000 |
| 2 | 30 | 7 | Friday | 7.410811e+09 | 1 | PERSONAL CARE | 98.500000 |
| 3 | 26 | 8 | Friday | 2.238404e+09 | 2 | PAINT AND ACCESSORIES | 420.045455 |
| 4 | 26 | 8 | Friday | 2.006614e+09 | 2 | PAINT AND ACCESSORIES | 420.045455 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 647049 | 39 | 191346 | Sunday | 3.239000e+10 | 1 | PHARMACY OTC | 645.823529 |
| 647050 | 39 | 191346 | Sunday | 7.874205e+09 | 1 | FROZEN FOODS | 645.823529 |
| 647051 | 39 | 191346 | Sunday | 4.072000e+03 | 1 | PRODUCE | 645.823529 |
| 647052 | 8 | 191347 | Sunday | 4.190008e+09 | 1 | DAIRY | 1277.500000 |
| 647053 | 8 | 191347 | Sunday | 3.800060e+09 | 1 | GROCERY DRY GOODS | 1277.500000 |
647054 rows × 7 columns
위 data set의 맨 오른쪽에 새로운 파생변수가 생성되었습니다. 7번 VisitNumber를 가진 고객은 98.5의 값 을 갖는 것으로 보아 다른 고객들보다 마이너한 물건 품목들을 구입했을 가능성이 높습니다. (실제로 Shoes나 personal care와 같은 품목은 구매 빈도수가 떨어지는 제품입니다.) 반대로 191347번 고객은 1277.5를 갖습니 다. 다른 고객들이 많이 구입하는 보편적인 품목을 구매했음을 알 수 있습니다. (GROCERY DRY GOODS와 같은 품목이 그렇습니다.)
-
FinelineNumber의 Count Sum값을 활용
이 변수는 위 변수 보다 간단합니다! 한 고객이 몇개의 FinelineNumber를 가지고 있는지 반영해주는 변수입니다. 즉, 몇개의 물품을 구매했는지에 대한 정보가 되겠습니다.
FineLineSum = train[['VisitNumber', 'FinelineNumber']].groupby('VisitNumber').count()
| FinelineNumber | |
|---|---|
| VisitNumber | |
| 5 | 1 |
| 7 | 2 |
| 8 | 22 |
| 9 | 3 |
| 10 | 3 |
| ... | ... |
| 191343 | 7 |
| 191344 | 5 |
| 191345 | 13 |
| 191346 | 17 |
| 191347 | 2 |
95674 rows × 1 columns
위 테이블을 data set에 붙이기만 하면 됩니다. 5번 고객은 1개의 물품밖에 구매하지 않았습니다. 이에 비해 8 번 고객은 22개의 물품이나 구매했네요! 이러한 정보들이 고객의 Type을 맞추는 데 도움을 줄 것입니다.
Modeling
새로 생성한 파생변수들만을 가지고 Modeling을 진행해보겠습니다. Model의 스펙은 앞서 base-line model과 동일합니다.
from keras import layers
from keras import models
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(x_train.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(38, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
return model
Kaggle leaderboard기준 7.80 의 Score를 기록했습니다. 앞서 파생변수를 생성하기 전에 비해 상당히 성능이 나빠진 모습을 확인할 수 있습니다.
이는 앞서 잠시 언급했었던 data의 sparsity때문입니다. DepartmentDescription 변수를 기준으로 만든 파생변수들의 수가 많은 데다 많은 행이 0의 값을 가지고 있기 때문에 model의 성능이 나빠질 수 밖에 없습니다. 이를 해결하기 위해서는 다양한 방법론들이 존재합니다. 본 분석에서는 Deep Learning model의 layer의 Dense층을 더 늘리는 방법을 통해 이 방법을 해결해보고자 합니다.
from keras import layers
from keras import models
def build_model():
model = models.Sequential()
model.add(layers.Dense(128, activation='relu', input_shape=(x_train.shape[1],)))
model.add(layers.Dense(128, activation='relu'))
model.add(layers.Dense(38, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
return model
앞 선 model에 비하여 각 층의 Dense를 128로 확장시켰습니다. 이는 변수가 늘어남에 따라 Deep Learning model이 학습할 parameter space를 확장시켜주기 위함입니다. 새로 학습한 model의 score는 2.27 입니다. Base-line model에 대비하여 향상된 성능을 보여줍니다.
cf) Random Forest Simulation
단순한 호기심으로 Random Forest에 자료를 학습시켜 보았습니다. 각 feature들은 bayesian optimization을 통해 tuning 해주었습니다.
from bayes_opt import BayesianOptimization
n_folds = 3
random_seed=6
# BayesianOptimization
def eval(n_estimators, max_depth, min_samples_split, min_samples_leaf):
params["n_estimators"] = max(n_estimators, 1)
params['max_depth'] = max(max_depth, 1)
params['min_samples_split'] = max(min_samples_split, 0)
params['min_samples_leaf'] = max(min_samples_leaf, 0)
rfc = RandomForestClassifier()
cv_result = cross_val_score(rfc, x_train, train_labels, cv=3, scoring='accuracy')
return min(cv_result)
params = {'max_depth': (10, 500)
,'min_samples_leaf': (1, 10)
,'min_samples_split': (1, 10)
,'n_estimators': (10, 500)
}
rfc_optimization = BayesianOptimization(eval, params, random_state=0)
init_round = 5
opt_round = 15
rfc_optimization.maximize(init_points=init_round, n_iter=opt_round)
rfc_optimization.max
params = rfc_optimization.max["params"]
op_clf = RandomForestClassifier(n_estimators=int(max(params["n_estimators"], 0)),
max_depth=int(max(params["max_depth"], 1)),
min_samples_split=int(max(params["min_samples_split"], 2)),
min_samples_leaf=int(max(params["min_samples_leaf"],2)), random_state=0)
op_clf.fit(x, labels)
### Get prediction
predictions = op_clf.predict_proba(x_test)
아무래도 딥러닝이 RF에 비해 추후에 나온 학습법이기 때문에 앞선 모델에 비해 성능이 안좋을 것이라고 생각했던 제 예측은 완벽히 오산이었습니다. Kaggle 기준 2.09 로 현재까지의 model들 중 가장 뛰어난 성능을 보여줬습니다.
시사점
-
단순한 딥러닝 모델은 정교한 머신러닝 모델보다 못하다?
앞서 살펴본 것처럼 딥러닝 모델에 비해 parameter tuning을 거친 Random Forest model이 더 좋은 성능을 보여줬습니다. 이에 대해 크게 두 가지 이유를 예상해보았습니다.
먼저, 우리가 가진 딥러닝 모델이 너무 단순합니다. 은닉 layer가 2개뿐이고 Dropout과 같은 over-fitting 방지 기법들도 적용해주지 않았기 때문에 정교하게 tuning된 RF에 비해 성능이 떨어지는 것이라고 예측해볼 수 있습니다.
다음으로는 RF의 Robustness때문입니다. Tree 기반인 RF는 다른 모델들에 비해 안정적이고 Robust한 모델로 알려져 있습니다. DepartmentDesciption 파생변수로 인해 data의 sparsity가 높아진 지금, 이러한 RF의 특징이 빛을 발한 것으로 생각됩니다. 따라서 PCA등과 같이 Spasity를 잡아주는 방법을 적용하여 딥러닝 모델에 적용한다면 더 좋은 성능을 얻을 수 있을 것 같습니다.
-
결측값 imputation
위 분석에서 결측값에 대한 처리는 따로 해주지 않았습니다. 그 이유는 결측값이 3,000여 개로 전체 dataset크기 대비 작았기 때문인데요. 그래도 이 부분에 대한 imputation이 이루어졌다면 더 좋은 분석이 되었을 것 같습니다.