
[Review] YOLOX
[Paper review] YOLOX
YOLO series의 2021년 가장 최신 버전, YOLO X 를 리뷰해보려고 합니다.
(이전 버전 리뷰: YOLO v1 review, YOLO v2 review, YOLO v3 review)
가장 최신의 YOLO series 논문을 살펴보면서 YOLO series는 마무리 하겠습니다!
Zheng Ge, Songtao Liu, Feng Wang, Zeming Li, Jian Sun. “YOLOX: Exceeding YOLO Series in 2021” arXiv preprint arXiv:2107.08430 (2021)
(본 리뷰의 모든 수식과 그림은 원 논문을 참고했습니다.)
YOLOX는 간단히 말하면 YOLO v3에 최신 object detection 기법들을 접목시켜 성능을 개선한 것이라고 할 수 있습니다. 그래서 논문 자체도 YOLO v3를 Baseline으로 하고 기법들을 순차적으로 add-on 해나가는 방향으로 저술되어 있습니다. (add-on 한개가 추가될 때마다 성능이 개선됩니다.)
이제 그 add-on을 하나씩 알아보겠습니다.
Decoupled head
YOLOX에서 적용한 add-on들 중 굉장히 큰 틀이 바뀌었다고 생각하는 지점이 두 가지가 있는데요. 그 중 하나가 바로 Decoupled head입니다.
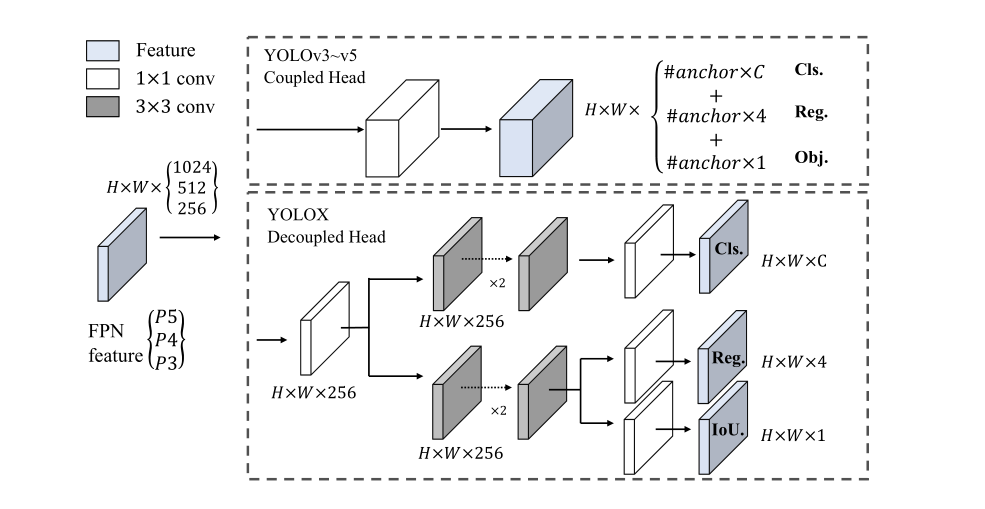
먼저 YOLO의 이전 버전들의 모델들이 object를 어떻게 detect 했는지 잠시 떠올려보죠. 먼저 anchor box를 통해 box boundary안에 object가 있는지 판단합니다. 있다면 detect을 위해 두 가지를 결정해야 하는데요. 먼저 object가 어떤 것인지를(강아지인지, 자동차인지 등) 정의하는 Classification 문제를 풉니다. 나머지 하나는 이미지(혹은 비디오) 내부에 어디까지가 object인지, 즉, box 크기를 어느정도로 가져가야 하는지를 결정하는 Regression 문제를 풉니다. (박스의 width, height 등의 값은 수치이기 때문에 이를 맞추는 것은 regression으로 보는 것 같습니다.) 이전 버전의 모델들은 이 문제들을 하나의 구조, 즉, 하나의 head에서 해결합니다. 그래서 YOLO v3의 경우 output의 dimension이 N x N x [3 * (4 + 1 + 80)] 이었죠! 여기서 4, 1, 80에 각각 regression 문제, object정의, classification 문제에 대한 모델의 답이 담겨있습니다.
문제는 이렇게 하나의 head에서 여러 문제를 해결하려다 보니 최적의 결과를 내지 못한다는 것인데요. 대표적으로 classification, regression 문제에 하나의 loss를 적용해야하는 문제 등을 들 수 있을 겁니다. 이에 이 두 문제를 따로 판단하고자 등장한 기법이 Decoupled head입니다. 저자들은 YOLO v3에 위 그림과 같이 Decoupled head를 적용하여 따로 따로 답을 적어내게 만들었습니다. 이에 따라서 output도 3가지가 추출되겠네요! ㅎㅎ
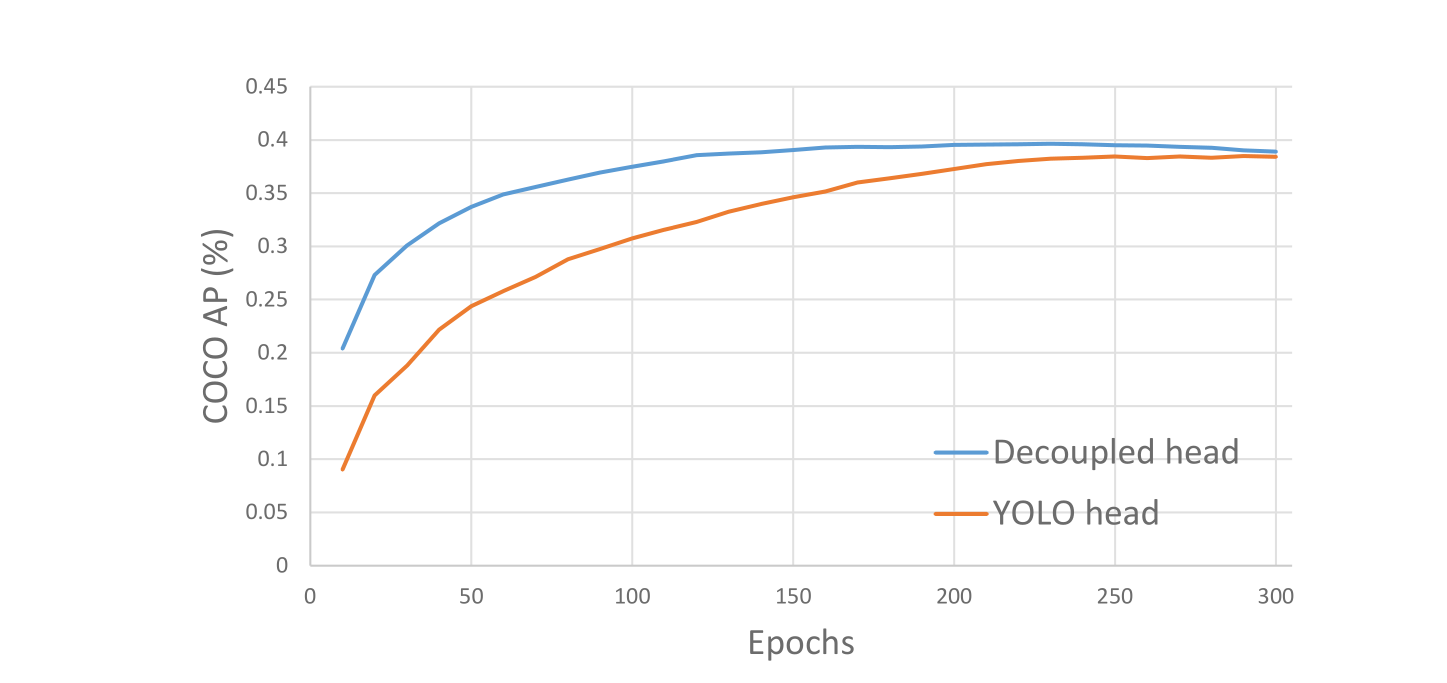
이렇게 Decoupled head 적용을 통해 모델이 적은 epoch을 가지고도 높은 수준의 AP에 더 잘 수렴하게 되는 결과를 가져온다고 합니다.
Strong data augmentation
두 번째 add-on, strong data augmentation입니다. 챕터 제목에서도 알 수 있듯이, 데이터를 여러 기법으로 증가시켜 모델의 성능을 좋게 만드는 것입니다. YOLOX에서 적용된 data augmentation기법은 Mosaic와 MixUp입니다.

기법 이름과 위 예시 그림에서 어떻게 데이터를 증가시키는지 유추가 가능합니다. Mosaic는 여러 이미지를 격자로 섞어서 data를 만들어내고 MixUp은 투명도를 올려 이미지를 겹침으로써 새로운 data를 만들어내네요!
Anchor-free
Decoupled head에 이어 YOLOX의 두 번째 큰 변경점, Anchor-free입니다. YOLO는 redmon의 V1 ~ V3 까지, 그리고 그 후에 나온 V4, V5 또한 Anchor-based로 만들어졌습니다. 그러나 앞선 리뷰에서도 살펴보았듯이 Anchor-based는 여러 문제가 있습니다. 먼저 anchor box의 수부터 위치까지 heuristic하게 지정해주어야 할 부분들이 많습니다. 또한 box의 수들로 인해 모델의 복잡성이 증가하게 되기도 합니다. 이에 최근 object detection에서는 anchor-free 매커니즘이 등장했는데요! YOLOX에서는 YOLO에서도 Anchor-free를 적용했습니다.
YOLOX에서 사용한 Anchor-free 알고리즘은 FCOS(Fully Convolutional One-Stage object detection)입니다.

왼쪽 그림에서 볼 수 있는 것처럼 최초로 object의 center라고 생각되는 지점을 predict 합니다. 이후에 center로부터 t, b, r, l, 즉, object의 경계선까지 box의 크기를 regression합니다. 이미지 내에 object가 두개라면 어떨까요? 만약 모델이 예측한 center point가 두 개의 object를 포함하고 있다면, 미리 정해진 object의 크기에 맞추어 각각 box의 크기를 regression할겁니다. 오른쪽 그림이 이를 잘 나타내줍니다. 만약 YOLOX 모델이 오른쪽 그림 속 point를 예측하였을 때, 미리 정해진 “사람”이라는 object의 크기만큼 regression하고 (주황색 box) “테니스채”라는 object크기 정도만큼 regression하여 (파란색 box) 최종적으로 detect할겁니다.
SimOTA
그렇다면 YOLOX가 예측한 center point가 object안에 포함되어 있다는 정보를 알아야만 그 point에서 regression을 진행할 수 있을겁니다. 아무 점에서나 다 box를 define한다면 그만큼 복잡해지고 detect 속도는 떨어질테니까요! 여기서 Object안에 포함되어 있다는 것을 Label Assignment라고 표현합니다. Sample data내에서 어떤 point들이 object를 포함하고 있는지를 할당해주는 작업입니다. object안에 존재하는 point를 Positive, 포함되어 있지 않은 point를 negative라고 합니다.
Label assignment에도 여러 가지 방법들이 있습니다. 저자들은 그 중에서 SimOTA를 사용했습니다. SimOTA는 Simple OTA의 줄임말로 OTA method를 simple하게 바꾼 버전이라고 생각하시면 되겠습니다.
(아무래도 YOLO의 속도에 중점을 두어 simple하게 개량한 것 같습니다.)
(OTA가 YOLOX 저자가 저술한 또 다른 논문이기 때문에 손쉬웠을 것으로 생각됩니다. 그래서 SimOTA를 선택한것 같.. )
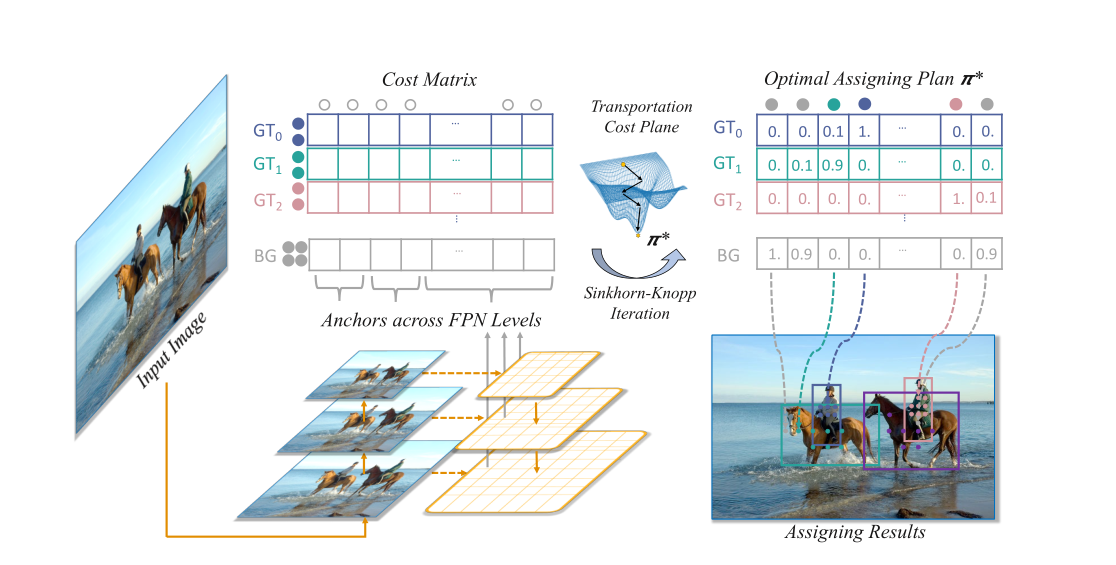
OTA는 Optimal Transport Assignment의 줄인 말로, 이름에서 나타나는 것처럼 Label assignment작업을 Optimal Transport 문제로 정의하고 이를 해결하는 방식으로 진행합니다. Optimal Transport는 간단하게 쿠팡을 생각하시면 편합니다! 물건을 팔고자하는 판매자들이 있고 이를 구매하고자 하는 고객이 있습니다. 여러 판매자와 여러 고객을 가장 효율적으로 matching시켜주는게 Optimal Transport의 개념입니다. (쿠팡의 새벽배송!)
이를 OTA에서는 Label이 정해지길 바라는 후보 point들이 구매자, pre-defined 되어 있는 Label의 종류들이 구매자라고 보는 것입니다. 위의 그림에서 보면 FPN에서 Label이 할당되기를 기다리고 있는 domain이 세팅됩니다. 세팅을 기다리고 있는 label은 말과 사람, 배경 등 총 5가지네요. 이를 가장 효율적으로 최적화하여 매칭시켜주는 것이 OTA가 할 일입니다. OTA는 이를 Sinkorn-knopp Iteration으로 해결합니다.

OTA는 다른 Label assignment 방법인 ATSS나 PAA에 비하여 경계선에 해당하는 부분에서의 할당이 더 정확하다고 합니다. 위 그림을 보면 여성과 아이가 겹쳐지거나 아이의 팔과 배경이 존재하는 등 애매한 빨간 동그라미 안의 구역에서 OTA는 정확하게 할당하는 것을 확인할 수 있습니다.
Experiment Results
이렇게 YOLOX에서 추가된 굵직한 add-on들을 살펴봤습니다. 결과를 확인해볼까요?
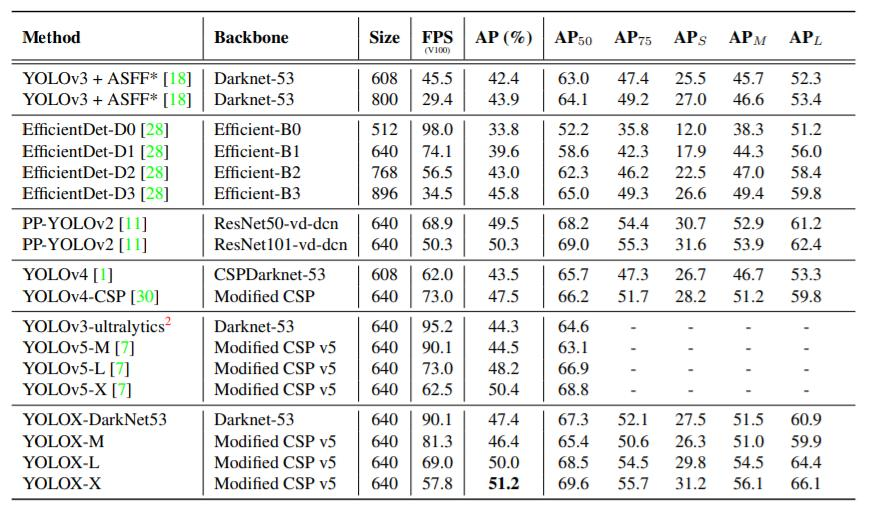
초당 detect하는 frame수를 뜻하는 FPS에서는 YOLO v5에 살짝 밀리긴 하지만 크게 나쁜 정도는 아니며 AP에서는 SOTA를 달성했네요!
원 논문에서는 YOLO v3뿐 아니라 YOLO v4, v5를 baseline으로 하고 위 add-on 들을 추가한 결과도 제시되어 있으니 관심있으신 분들은 실제 논문을 참고해주세요!