
Coursera Computer Vision Course 과제 정리
Coursera Computer Vision Course 과제 정리
장장 1월부터 4월까지 3개월을 질질 끌었던 (심지어 다 듣지도 못함)
Coursera의 “Deep Learning in Computer Vision”(HSE Univ.) 수업에서 나왔던 과제들을 간단하게 정리해보고자 합니다.
Week 1
1주차 과제는 주어진 gray scale 이미지의 윤곽선을 detection하는 것입니다. 이 과정에서 Canny Edge Detector 라는 것을 사용하게 되는데요! 작동 매커니즘을 간략히 살펴보겠습니다.
1. Noise Reduction
제일 먼저 이미지의 Noise를 제거해줍니다. Canny detector는 윤곽선을 잡아내기 위해 미분을 하게 되는데 이 때 Noise가 끼어있으면 임계점을 찾아내기가 힘듭니다. 이에 Gaussian kernel을 이용한 Blur처리를 통해 이미지를 흐릿하게 바꿔줍니다. (핵심 포인트만 남기는 거죠!)
2. Calculating gradient
이렇게 smoothing된 이미지를 $I$라고 할 때, 이 이미지의 픽셀에서 그 값이 뚜렷하게 구분되는 지점이 어디인지(Slope), 또 그 곳에서 이미지 값의 강도는 얼마인지(Magnitude)를 찾아야 윤곽선을 찾을 수 있습니다. 이를 찾기 위해 Sobel Kernel 을 활용합니다. 구하는 수식은 아래와 같습니다.
\[\begin{gathered} |G| = \sqrt{I_x^2+I_y^2}, \\ \theta(x,y) = arctan(\frac{I_y}{I_x}) \\ where\ G\ is\ Magnitude\ and\ \theta\ is\ the\ Slope \end{gathered}\]3. Non-maximum suppression
위에서 찾아진 Magnitude를 가지고 진짜 Maxumum, 즉, 더욱 명확한 픽셀 경계선을 찾기 위해 Non-maximum value들을 지워줍니다. Neighbor에 있는 점들끼리 $G$를 비교해서 이루어지게 됩니다.
4. Double Threshold & Edge tracking
이렇게 찾아진 윤곽선 후보들 중에서도 아직도 noise들이 섞여 있습니다. 이를 더 명확히 하기 위해서 Low Threshold, High Threshold를 설정해서 이 범위 밖에 있는 값들은 이제 윤곽선으로 확정해줍니다.
Threshold들 사이에 있는 값들의 경우 Edge tracking을 통해 윤곽선으로 인정해줄 수 있는지를 최종 판단하는 절차를 거칩니다.
이제 과제를 통해 Canny detector를 적용한 모습을 살펴보겠습니다. 과정은 복잡하지만 코드를 통해 간단하게 구현할 수 있습니다. 먼저 edge를 detect해야 하는 이미지의 모습입니다.

이제 이 이미지에 Canny edge를 적용해보겠습니다.

보시는 것처럼 성과 나무의 경계선 만이 뚜렷하게 남은 것을 확인할 수 있습니다. 성 이미지의 3가지 모습들에서 구름의 모양이 각기 다른데, 이 부분에 대한 윤곽선도 잡아내는 부분이 흥미롭네요!
Week 2
2주차 과제는 Facial Point Detection입니다. 말 그대로 얼굴의 다양한 포인트들을 잡아내주는 영역이죠! 다양한 사람 이미지들에서 정확히 눈썹, 눈, 코, 입 등을 잡아내주는 과제입니다. 일련의 코드 작업을 통해 Point를 찍어주면 다음과 같습니다.
import matplotlib.pyplot as plt
from matplotlib.patches import Circle
def visualize_points(img, points):
fig,ax = plt.subplots(1)
ax.set_aspect('equal')
# Show the image
ax.imshow(img)
for i in range(int(len(points)/2)):
circ = Circle( ( (points[i*2] + 0.5) * 100, (points[(i*2 + 1)] + 0.5) * 100 ) ,1, color="red")
ax.add_patch(circ)
# Show the image
plt.show()
visualize_points(imgs[1], points[1])
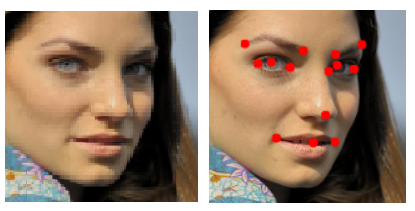
이러한 이미지들은 아래와 같이 좌우 flip을 통해 모델에 넣을 때 Data augmentation 효과를 볼 수 있습니다.
def flip_img(img, points):
f_points = zeros(int(points.shape[0]))
reverse_points = points[::-1]
for i in range(int(points.shape[0]/2)):
f_points[i*2] = - reverse_points[i*2 + 1] # 음수 부호: X축 기준으로 좌우 반전 해주어야하기 때문
f_points[i*2 + 1] = reverse_points[i*2]
return f_img, f_points
f_img, f_points = flip_img(imgs[1], points[1])
visualize_points(f_img, f_points)
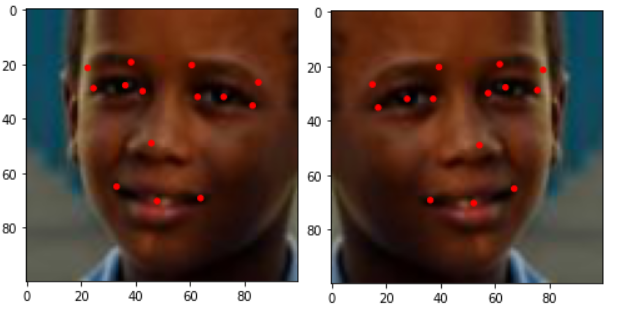
물론 이런 이미지를 가지고 모델에 피팅해서 테스트 셋 이미지에서 facial point를 찾는 것이 과제의 완성이었지만.. 파일을 잃어버림…그래서 구질구질 코드까지 삽입;;
Week 3
3주차 과제는 Face detection입니다. 여러 종류의 사람들의 이미지(FDDB dataset)에서 얼굴만 정확하게 추출해내는 것이 과제의 목표입니다. 일종의 얼굴 object detection이라고도 할 수 있을 것 같습니다.
먼저 이미지들과 Target을 살펴보겠습니다.

다음과 같이 약 1,000여 장의 사람들의 이미지가 존재하고 각 이미지마다 얼굴을 특정하는 Bounding Box가 있습니다. 과제의 목표는 Test set 이미지에서도 정확한 Bounding box를 그려줄 수 있는지 입니다.
출제자의 의도는 Positive bounding box (주어진 label, 실제 사람 얼굴)와 Negative bounding box (사람이 얼굴이 아닌 다른 곳)를 활용하여 Binary classification으로 model이 얼굴을 찾아낼 수 있도록 하는 것입니다. 이를 위해서 이미지의 shape limit을 바탕으로 얼굴이 아닌 곳에 해당하는 negative bounding box를 임의로 생성하였습니다. 그 비율은 5:5 정도입니다.
 Top 2: Positive box, Bottom 2: Negative box
Top 2: Positive box, Bottom 2: Negative box
과제에서 사용한 모델은 Lenet (LeCun, Y., Bottou, L., Bengio, Y. and Haffner, P., 1998. Gradient-based learning applied to document recognition. Proceedings of the IEEE, 86(11), pp.2278-2324)입니다. Keras를 이용해서 간단하게 구현할 수 있으며 데이터의 명확성 때문인지 epoch을 많이 주지 않아도 training accuracy 높게 나타납니다.
그럼 fitting된 모델을 가지고 test set에서도 얼굴을 잘 잡아낼 수 있을 지 살펴보겠습니다.

파란색 box가 모델이 얼굴이라고 예측한 부분입니다. 언뜻 잘 맞추는 것도 같지만 자세히 살펴볼수록 부정확한 모습입니다. 특히, 얼굴을 전부 포함하지 못하고 부분 부분만을 잡아내고 있습니다. 아무래도 netgative box와 postive box를 동시에 넣고 fitting을 시키다 보니 발생하는 문제점인 것 같습니다. 또한 이미지의 size가 작고 그에 비해 box 사이즈는 크다보니 정확히 포착을 못하는 것 같습니다. 물론 더 하이엔드 모델을 쓴다거나 model을 더 정교하게 fitting하는 방법으로 performance는 개선될 여지가 매우 많아 보입니다. (강의도 다 못들었는데 성능 개선까지 할리가 없습니다 ㅠㅠ)