
NLP, Text mining start!
NLP & Text Mining Study
19년도 1학기 Data Science Lab 스터디 주제는 Text Mining입니다.
매주 1회 NLP(Nature Language Processing) 기법 중 Text Mining에 활용할 수 있는 알고리즘들을
공부하여 포스팅할 계획입니다.
이번 포스트에서는 본격적인 알고리즘 소개에 앞서 NLP가 어떤 프로세스를 가지고 있는 지, 어떤 방법
으로 Language data를 처리하는 지 먼저 살펴보도록 하겠습니다.
(본문에 앞서 본 포스트는 ratsgo님의 블로그, Stanford University School of Engineering의 NLP강의를 참고하여 작성하였음을 미리 밝힙니다.)
Why is NLP hard?
기본적으로 인간의 언어를 데이터로 표현하고 분석하는 일은 결코 쉬운 작업이 아닙니다.
인간의 언어는 동음이의어와 같이 문맥 상 해석이 필요한 경우가 잦고, 동일한 의미 내에서도
단어들의 뉘앙스와 같은 모호한 차이점이 발생합니다. 때로는 신조어나 문법에 맞지 않는 구어적
표현으로 분석을 어렵게 하는 경우도 많습니다.
이렇게 어려운 인간의 말을 잘 분석해내기 위해 자연어 처리에는 다양한 분야의 지식들이 서로
연관되어 있습니다.
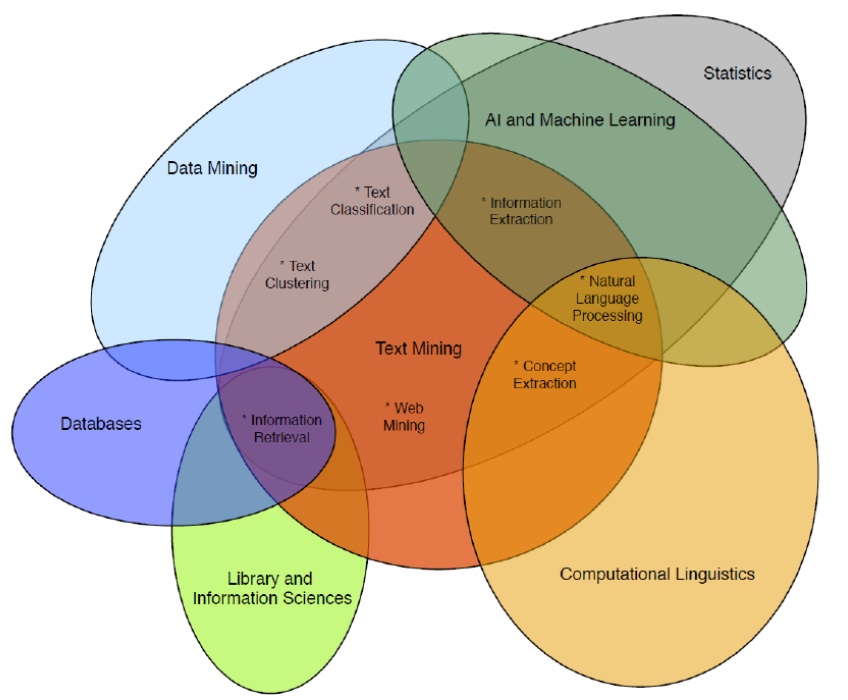
먼저 NLP는 본질적으로 언어학에 큰 뿌리를 두고 있습니다. 언어학에서 말을 구분하는
음운론(Pnomology), 형태론(Morphology), 통사론(Syntax), 의미론(Senmantics) 등의 아이디어를 기반
으로 문장을 구분하고 단어를 파악합니다.
또한 문장들을 계산할 수 있는 벡터로 representation하고 이를 분석하는 과정에서 다양한 수학적,
통계적 지식이 활용됩니다.
Basic NLP Process
다음 그림은 NLP 처리 과정을 한 눈에 보기 쉽게 정리한 것인데 이를 이용하여 기본적인
NLP 프로세스를 따라가보겠습니다.
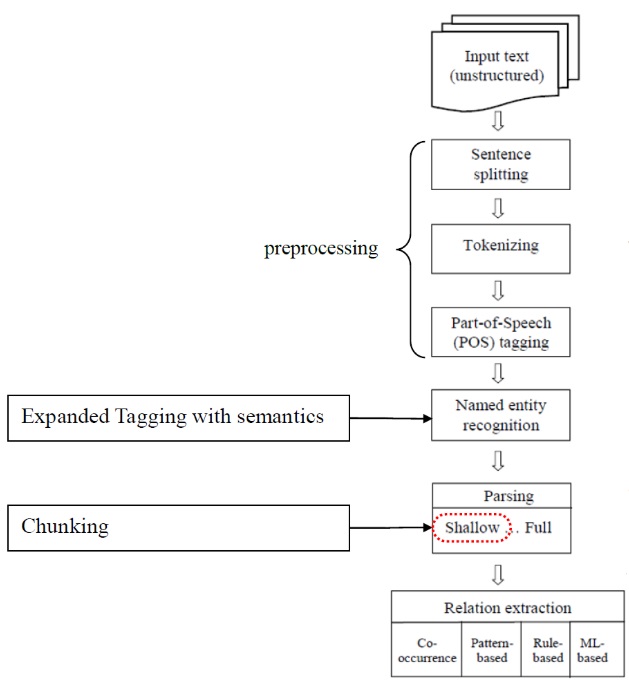
1. Sentence Splitting
일반적으로 우리가 분석하고자 하는 Text Data를 말뭉치, Corpus라고 지칭합니다.
컴퓨터에게 이러한 Corpus는 분석할 수 없는 언어들의 나열일 것이므로 우리는 이를 적절히
representation 해주는 것이 필요합니다. 이 과정의 첫 번째 단계가 Sentence Splitting입니다.
단어의 의미 그대로 Corpus를 문장별로 끊어준다는 의미입니다. 보통 마침표, 느낌표, 물음표 등으로
구분합니다.
2. Tokenize
토큰(Token)은 의미를 가지는 문자열을 지칭합니다. 작게는 형태소에서 크게는 단어에 이르기까지
독립적인 의미를 갖는 문자열을 의미하는 것입니다. Tokenize단계에서는 앞 서 끊어준 문장들을 다시
의미를 가지는 토큰들로 나누어 주는 것을 의미합니다.
독립적인 의미를 갖는 문자열을 찾는 방법은 언어별, 쓰임새별, 문법별로 다양한 차이가 나타날 수
있고 때때로 Sentence Splitting 기법보다 더 난해한 작업이 되기도 합니다.
3. POS Tagging (Part-Of-Speech Tagging)
포스태깅은 앞서 나뉘어진 토큰들에 품사를 지정해주는 작업(Tagging)을 말합니다.
토큰에 품사를 정해주기 위해서는 단어간의 관계나 문장 내 쓰임새에 대한 분석 능력이 필요할텐데요.
다양한 머신러닝 계열 기법들이 활용되어 포스태깅 작업을 진행하고 있습니다.
더하여 Named entity recognition은 포스태깅 작업이 확장된 개념으로 각각의 태그별로 사람의
이름이나, 지역 이름, 회사 이름과 같은 고유 명사를 분류해주는 작업을 말합니다.
여기까지의 Sentence Splitting과 Tokenize, 포스태깅을 묶어 자연어 데이터의
전처리 작업(Preprocessing)이라고 볼 수 있겠습니다.
실제 Corpus예시를 가지고 전처리 작업 실습을 진행해보도록 하겠습니다.
파이썬의 KoLNPy 패키지를 활용하면 전처리 일련의 작업들을 손 쉽게 처리할 수 있습니다.
다음은 KIA타이거즈 양현종 선수 관련 기사를 발췌하여 실습을 진행한 결과입니다.
from konlpy.tag import Twitter
Twitter.pos('돌을 던질 수 없다. KIA타이거즈 에이스 양현종이 개막 이후 부진에 빠졌다. 3경기에 등판해 14이닝을 던져 14자책점을 기록했다. 왜 그럴까?')
('돌', 'Noun'),
('을', 'Josa'),
('던질', 'Verb'),
('수', 'Noun'),
('없다', 'Adjective'),
('.', 'Punctuation'),
('KIA', 'Alpha'),
('타이거즈', 'Noun'),
('에이스', 'Noun'),
('양현종', 'Noun'),
('이', 'Josa'),
('개막', 'Noun'),
('이후', 'Noun'),
('부진', 'Noun'),
('에', 'Josa'),
('빠졌다', 'Verb'),
('.', 'Punctuation'),
('3', 'Number'),
('경기', 'Noun'),
('에', 'Josa'),
('등', 'Noun'),
('판해', 'Verb'),
('14', 'Number'),
('이닝', 'Noun'),
('을', 'Josa'),
('던져', 'Verb'),
('14', 'Number'),
('자책점', 'Noun'),
('을', 'Josa'),
('기록', 'Noun'),
('했다', 'Verb'),
('.', 'Punctuation'),
('왜', 'Noun'),
('그럴까', 'Adjective'),
('?', 'Punctuation')
결과를 살펴보면 먼저 마침표, 물음표 등을 기준으로 문장이 나뉘어진 것을 볼 수 있습니다.
또한 독립적인 의미를 갖는 형태소별로 각 문장이 잘 나뉘는 것을 볼 수 있으며, 영어나 특수문자도
잘 구별됩니다. 마지막으로 각 단어들에 품사들이 잘 주어져 있어 포스태깅 작업도 이상없이
진행되었음을 알 수 있습니다.
4. Syntactic, Semantic Analysis
일반적인 데이터 분석 과정에서 데이터 전처리가 끝나면 알고리즘을 적용하듯이, 자연어 처리에서도
데이터 전처리 후 Corpus에서 여러 의미를 도출하기 위해 알고리즘을 적용합니다.
Corpus 내의 문장, 단어의 관계나 의미를 파악하는 데 있어 크게 두 가지 관점으로 나누어 볼 수 있습니다.
먼저, 통사론적(Syntactic) 분석 방법이 있습니다. 통사론적 분석은 문장이 가지는 문법 구조,
특정 단어가 주위 단어들과 어떤 구조로 얽혀있는 지에 대해 분석하는 방법입니다. 자연어 데이터를
Parsing한다는 개념이 바로 통사론적 분석 방법에 속합니다. 주로 앞서 진행된 전처리 과정에서
나타나는 토큰들과 태깅들을 바탕으로 핵심 단어를 선택해서 주변 단어들과의 관계를 보는 방식으로
진행됩니다. 올바른 전처리 과정, Parsing 방법을 통해 컴퓨터는 주어진 Corpus의 구조를 더욱 명확하게
파악할 수 있게 됩니다.
두 번째는 의미론적(Semantic) 분석 방법입니다. 앞 서 통사론적 분석 방법이 문법이나 품사와
같은 문장의 전반적인 구조에 대해서 살펴보았다면, 의미론적 분석 방법은 특정 단어, 구, 문장 등이
가지는 의미에 방점을 두고 분석하는 방법입니다. CNN, RNN과 같은 Deep Learning 기법을 통해
단어의 의미를 학습하게 되며, 이를 기반으로 더 큰 단위인 구, 문장 등으로 확장해가며 Corpus 내의
Semantic 정보들을 분석하게 됩니다.
Syntactic과 Semantic 모두 Text의 관계를 파악하는 데 중요한 개념입니다. 두 분석을 위한 알고리즘
들은 다양하게 준비되어 있습니다. Corpus의 특징, 분석의 목적 등에 따라 적절한 알고리즘을 사용하여
Corpus를 적절하게 분석하는 것이 Text Mining의 핵심이라고 할 수 있습니다.
지금까지 NLP 분석 과정에 대해 간략하게 살펴보았습니다. 다음 포스트 부터는 본격적으로
Text Mining 알고리즘들에 대해 하나씩 공부해 보겠습니다.