
[Review] Efficient Det
[Paper review] Efficient Det
가볍고 효율적인 방식임을 강조하지만 정확성도 놓치지 않은 구글의 Efficient Det 논문을 리뷰해보겠습니다.
Tan, Mingxing, Ruoming Pang, and Quoc V. Le. “Efficientdet: Scalable and efficient object detection.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020.
(본 리뷰의 모든 수식과 그림은 원 논문을 참고했습니다.)
Architeture
Efficient Det은 구글 브레인의 이전 논문인 Efficient Net을 Backbone으로 활용한 Object detection 버전 모델입니다. 논문 곳곳에서 효율적이고 가볍다는 언급을 자주 할만큼 효율성에 집중한 듯 하지만 정확도 또한 20년 기준 SOTA를 달성한 굉장한 모형입니다. 기본적으로 YOLO 등과 비슷하게 One stage detection 구조를 가지고 있습니다. 자세한 아키텍처는 아래와 같이 표현할 수 있습니다.
\[Efficient\, Det = BiFPN + Compound\, Scaling + Efficient\, Net\]
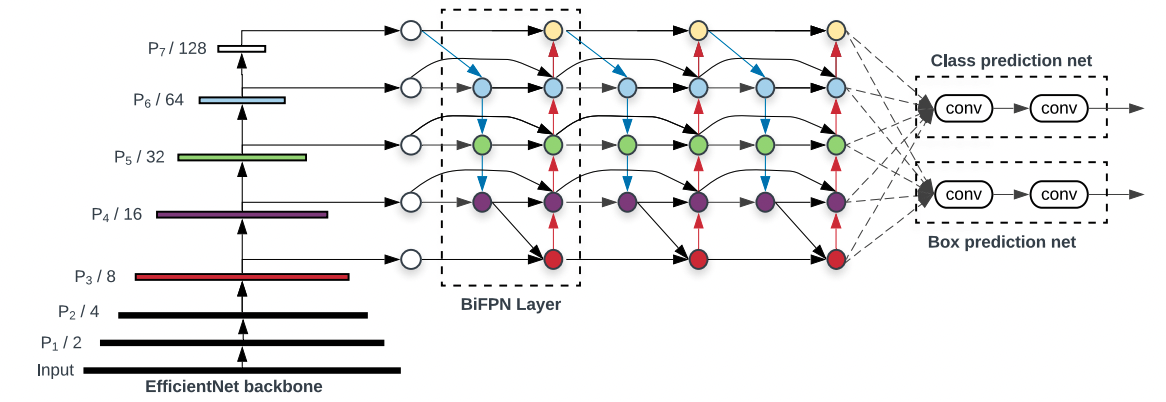
Backbone인 Effcient Net외에 Bi-FPN과 Compound Scaling이라는 두 기법이 추가로 더 적용되어 있는 것을 확인하실 수 있습니다. 지금부터 두 방법이 어떤 것인지 알아보도록 하겠습니다.
Bi-FPN
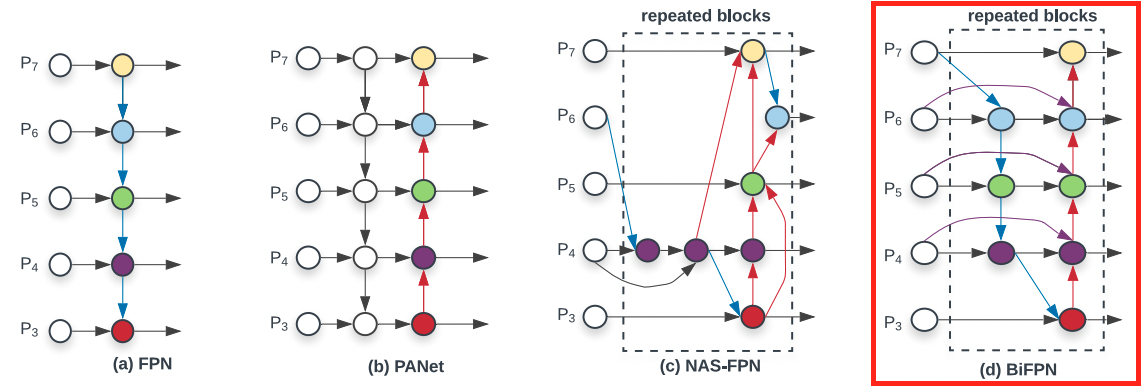
기본적으로 Object detection 알고리즘들은 이미지나 비디오의 feature를 기준으로 detecting을 합니다. 이 때, 다양한 resolution에서 feature를 받아 분석하는 것을 multi-scale feature fusion 이라고 합니다. 대표적인 방식으로는 FPN(Feature Pyramid Network)이 있죠! FPN은 각 scale에서 feature를 받을 수 있지만 Top-Down 방식만 가능하다는 단점이 있습니다. 이에 Bottom-Up flow도 추가한 것이 PANet입니다. 가장 정확하다는 평가를 받는 feature fusion 방식입니다.
하지만 이러한 PANet은 굉장히 많은 parameter를 가질 수 밖에 없기 때문에 cost가 늘어난다는 단점이 있습니다. (이 단점을 해결하기 위해 NAS-FPN이 등장했지만 정확도가 떨어집니다.) Bi-FPN은 본 논문에서 제시하는 방법론으로, 정확성을 담보하면서도 PANet보다 효율적인 구조입니다. 개인적으로는 PANet 기본 구조에 효율성을 갖도록 몇 가지를 수정한 방법이라고 보여집니다.
우선 Bi-FPN의 Scale connection 부분부터 살펴보겠습니다. Bi-FPN은 PANet과는 달리 input edge만을 갖는 노드는 없게 설계하여 parameter를 줄였습니다. 또한 Same level의 input node는 바로 bottom-up 단계의 output node로 연결하여 많은 cost없이 feature fusion이 일어나도록 설계했습니다. 마지막으로 Top-down / Bottom-up path들을 NAS-FPN처럼 반복함으로써 정확도를 확보했습니다.
이렇게 연결된 feature들을 fusion하는 방법에 대해 알아보겠습니다. 기본적으로 각 Input들을 그냥 결합할 경우 scale에 따라 가중치가 달라지기 때문에, 이를 반영하여 결합하는 것이 각 scale의 주요 특징들을 반영하는 데 중요합니다. 본 논문에서는 Fast Normalized fusion을 사용해서 빠르게 결합하는 방식을 사용했습니다.
\[O = \sum_i \frac{w_i}{\epsilon+\sum_j w_j} * I_i\]Compound Scaling
앞 서 Bi-FPN에서 반복을 통해 feature들을 파악한다고 했는데요! 그러면 layer의 반복 수는 어떻게 정하면 될까요? 또 Efficient Det의 scale을 키울 때, 각각의 channel이나 layer들은 어떻게 정해야 효율적으로 scale up 할 수 있을까요? 이런 것들을 정하는 것이 Compound Scaling 파트입니다.
결론적으로 말하면 케이스 별로 optimize해주는 것은 아니고 저자들이 실험을 통해 최적의 궁합을 찾았다는 것입니다. 저자들은 compound coefficient $\phi$를 사용하여 각 scale에서의 layer 수, channel 수, dimmension 등을 컨트롤합니다. Compound coefficient가 컨트롤하는 정보들은 다음과 같습니다.
\[W_{bifpn} = 64 * 1.35^\phi \\ D_{bifpn} = 3 + \phi \\ D_{box} = D_{class} = 3 + [\phi/3] R_{input} = 512 + \phi * 128\]
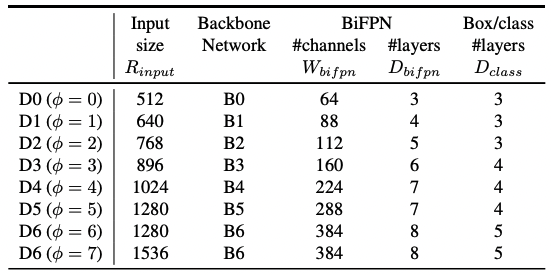
보시는 것처럼 각 scale별로 자동적으로 coefficient들이 결정되는 것을 볼 수 있습니다. 이를 통해 각 feature들이 조화롭게 학습되기를 바라는 것입니다.
Experiment Results
Efficient Det이 기존 Object Detection 방법들에 비해 얼마나 좋은 성능을 갖고 있는지 확인해보겠습니다.
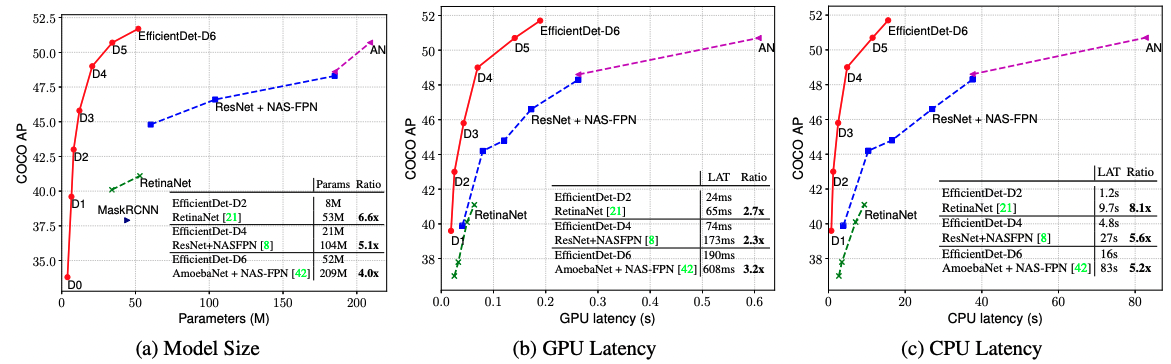
논문에서 다양한 실험 결과들을 확인할 수 있지만 가장 대표적인 것으로 가져왔습니다. 위의 plot을 보시면 모델의 정확도가 다른 기존 방법론들과 비슷한데도 model의 parameter가 가장 작으며, hardware latency도 작음을 알 수 있습니다. 작지만 빠르고 강력한 모델이 바로 Efficient Det이라고 할 수 있겠네요!
마무리
지금까지 Efficient Det에 대해 살펴보았습니다. 개인적으로는 parameter 수를 최대한 줄이며 효율성을 추구했는데도 성능이 증가한 부분이 인상 깊습니다. 다만 Compound scaling 부분에서 처럼 hueristic하게 parameter들을 결정해도 모든 케이스에 대해서 같은 성능을 담보할 수 있을지 궁금합니다. (물론 굉장히 유명한 모델인만큼 그럴 것이라 믿어 의심치 않습니다 ㅎㅎ)
Reference
- Paper: Efficient Det
- Github: google/automl/Efficient Det